










Genetický kód z pohledu matematiky
| 7. 6. 2012Když byla r. 1953 objevena struktura DNA (viz obr. 1), začaly prvotní pokusy o určení genetického kódu. Slavného fyzika ruského původu George Gamowa uchvátila myšlenka, že k vysvětlení druhové rozmanitosti a fungování genů by mohla být použita kombinatorika a teorie čísel. Jako jeden z prvních si uvědomil, že 20 druhů aminokyselin, z nichž se skládají proteiny, nemůže být kódováno dvojicemi nukleotidů, protože existuje jen 16 = 4 ∙ 4 různých dvojic ze čtyřprvkové abecedy {A, C, G, T}, kde A je adenin, C cytosin, G guanin a T thymin. Proto vymýšlel, jak tento nedostatek obejít. Gamow v práci z roku 1954 navrhl tzv. překryvný degenerovaný kód, v němž se sice uvažují jen dvojice nukleotidů, ale příslušná aminokyselina je přiřazena až po přečtení prvního nukleotidu z další dvojice (např. AC GA …). Je zřejmé, že takový kód (angl. partial overlapping code) by předepisoval velice přísné podmínky na řazení jednotlivých aminokyselin. Později se ukázalo, že tudy cesta nevede.
 Genetický kód se pokoušel rozluštit i fyzik Francis H. C. Crick, spoluobjevitel struktury DNA. Crickovu genialitu můžeme ilustrovat na tzv. kódech bez čárky. Crick správně předpokládal, že danou aminokyselinu kóduje trojice nukleotidů, kterých je ze čtyřprvkové abecedy celkem 4 ∙ 4 ∙ 4 = 64. Dobře věděl, že tyto triplety (kodony) nejsou nikterak odděleny, tj. není jasné, kde daná trojice začíná a odkud se má vlastně začít číst genetická informace.
Genetický kód se pokoušel rozluštit i fyzik Francis H. C. Crick, spoluobjevitel struktury DNA. Crickovu genialitu můžeme ilustrovat na tzv. kódech bez čárky. Crick správně předpokládal, že danou aminokyselinu kóduje trojice nukleotidů, kterých je ze čtyřprvkové abecedy celkem 4 ∙ 4 ∙ 4 = 64. Dobře věděl, že tyto triplety (kodony) nejsou nikterak odděleny, tj. není jasné, kde daná trojice začíná a odkud se má vlastně začít číst genetická informace.
Předpokládal, že trojice AAA, CCC, GGG a TTT nic nekódují a že na zbylých 60 trojicích je zavedeno 20 tříd ekvivalence. Trojice nukleotidů považoval za ekvivalentní, pokud cyklická permutace převáděla jednu trojici na druhou, např. AAC, ACA a CAA jsou tři ekvivalentní trojice, s nimiž už žádná jiná trojice ekvivalentní není. Tím dostal vzájemně jednoznačné zobrazení mezi 20 aminokyselinami a 20 třídami ekvivalence. Tento kód měl navíc tu výhodu, že řetězec
…AAC AAC AAC GAC GAC TAC…
by kódoval stejný protein jako řetězec
…AA CAA CAA CGA CGA CTA C…,
který vznikne cyklickou permutací každého tripletu, a přitom je pořadí nukleotidů v obou řetězcích stejné. V tomto konkrétním (umělém) případě by tedy nezáleželo na tom, od kterého nukleotidu z dané trojice se čte genetická informace (proto kód bez čárky).
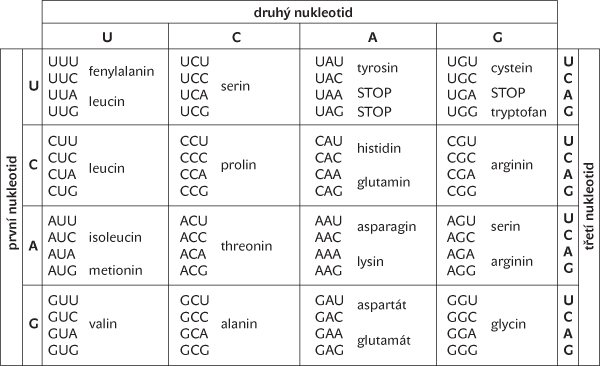
V roce 1961 však M. W. Nirenberg a J. H. Matthaei objevili, že triplet TTT kóduje aminokyselinu fenylalanin. Protože triplet TTT byl v Crickově kódu bez čárky vyloučen, ukázal se tento kód také nesprávný. O pět let později pak Marshall Nirenberg stanovil definitivní podobu standardního genetického kódu (tab. I), za niž dostal Nobelovu cenu.
Teorie kódování
Teorie kódování je matematická disciplína, která se zabývá kódováním a dekódováním zpráv a vlastnostmi kódů samotných. Přitom se kódem rozumí jen množina kódových slov, což jsou sekvence znaků splňující určitá pravidla. Sémantice, tj. významu kódových slov, se teorie kódování nevěnuje.
Praktické využití nalézá teorie kódování především v informatice (včetně bioinformatiky), v oblasti telekomunikací, zpracování signálů a v zabezpečovací technice. Přitom řeší hlavně dva (zpravidla protichůdné) problémy: jak přenést co největší množství informace s danými omezenými prostředky a jak informaci co nejlépe ochránit před zkreslením.
Definice kódu
Při kódování používáme dvě množiny znaků: množina A − zdrojová abeceda − slouží k zápisu původní (nezakódované) zprávy. Její prvky nazýváme zdrojové znaky. Množina B, pomocí které zapisujeme zakódovanou zprávu, se nazývá kódová abeceda a její prvky jsou kódové znaky. Pokud budeme jako příklad kódu zkoumat Morseovu abecedu, bude její zdrojovou abecedou množina všech písmen latinské abecedy, číslic a několika interpunkčních znamének, která mají v morseovce svůj ekvivalent. Kódovou abecedou morseovky je množina skládající se z tečky, čárky a mezery (neboli z krátkého tónu, dlouhého tónu a pomlky). Poznamenejme ještě, že teorie kódování chápe abecedu jen jako množinu, to znamená, že v abecedě není určeno pořadí písmen.
Jako slovo v abecedě A, resp. B označujeme libovolnou konečnou a neprázdnou posloupnost prvků z A, resp. z B. Proces zvaný kódování přiřadí každému znaku zdrojové abecedy jedno slovo kódové abecedy. Tato slova nazveme kódovými slovy a množina všech kódových slov se nazývá kód. Ostatní slova v kódové abecedě B jsou nekódová.
Například při kódování pomocí Morseovy abecedy přiřadíme znaku „A“ kódové slovo „∙ –“, znaku „B“ přiřadíme „– ∙ ∙ ∙“ a tak dále. Množina všech těchto kódových slov by se měla nazývat správně Morseův kód; nekódové slovo je například posloupnost „∙ ∙ – – – ∙ – –“, která je příliš dlouhá.
Kód můžeme zkoumat i bez znalosti kódování, pomocí kterého vznikl, jen jako množinu slov v kódové abecedě. Posloupnosti „gtyfur“ nebo „koloběžka“ jsou slova v české abecedě. Zatímco první z nich k ničemu nepotřebujeme (protože v češtině nemá žádný význam, což je ovšem z pohledu teorie kódování nepodstatné), druhou můžeme běžně použít. Definujeme-li kód zvaný „slova českého jazyka“ jako množinu všech slov, která můžeme v českém textu použít, je „koloběžka“ kódové slovo a „gtyfur“ slovo nekódové. Obecně tedy na vlastnosti kódu neklademe žádné požadavky. Speciální postavení mají blokové kódy, jejichž všechna slova mají stejnou délku. Příkladem je ASCII kód pro kódování znaků v počítači nebo, jak uvidíme později, genetický kód. Naproti tomu slova Morseovy abecedy (sekvence „∙ –“, „– ∙ ∙ ∙“ atd.) mají různou délku – jde o kód, který není blokový.
U některých blokových kódů je možné kódové slovo rozdělit na dvě části: informační část složenou z informačních znaků a kontrolní část tvořenou kontrolními znaky. Při nejpřehlednějším tzv. systematickém kódování se za slovo, které chceme zakódovat a které bude tvořit informační část kódového slova, přidá určitý počet kontrolních znaků. Například za slovo „mayday“, které chceme vyslat (a které obsahuje informaci o tom, jak se máme), přidáme totéž slovo ještě dvakrát a dostaneme kódové slovo „maydaymaydaymayday“, jehož prvních šest znaků je informačních a posledních dvanáct znaků je kontrolních, sloužících příjemci k ověření neporušenosti zprávy, popřípadě i k jejímu opravení. Častěji se setkáme s lépe ukrytými kontrolními znaky například v desetimístném rodném čísle (jeho poslední, desátá číslice je kontrolní a je zvolena tak, aby celé rodné číslo bylo dělitelné jedenácti), VIN automobilu (v 18 z jeho 19 znaků je zakódován výrobce, typ vozu, rok výroby a podobně, zatímco devátá číslice je kontrolní), v čísle platební karty, ISBN, EAN a mnoha jiných číselných kódech, které nás obklopují.
Blokový kód, který má délku slova n a ve kterém je k informačních a n−k kontrolních znaků, označujeme jako (n,k)-kód. Podíl k/n se nazývá informační poměr kódu a udává nám, jaký je podíl „skutečně užitečné“ informace v kódované zprávě.
Genetický kód v mRNA
Podíváme-li se na genetický kód v mRNA sloužící k syntéze proteinů (k translaci) očima teorie kódování, vidíme, že jde o blokový kód s délkou slova 3 a s kódovou abecedou {A, C, G, U}. Jeho kódová slova jsou trojice nukleotidů (triplety, kodony). Protože každý kodon (kromě terminačních kodonů UAA, UAG a UGA) kóduje jednu aminokyselinu, můžeme množinu všech aminokyselin {alanin, arginin, asparagin, aspartát, cystein, glutamin, glutamát, glycin, histidin, isoleucin, leucin, metionin, fenylalanin, prolin, serin, threonin, tryptofan, tyrosin, valin} považovat za zdrojovou abecedu tohoto kódu.
V tripletu nejsou žádné kontrolní znaky; všechny tři nukleotidy mají funkci informačních znaků. Genetický kód v mRNA je tedy kvaternární (mající čtyřprvkovou abecedu) blokový (3,3)-kód. Jeho informační poměr je 3/3 = 1, takže místem rozhodně neplýtvá. Druhá stránka věci, jak uvidíme za okamžik, je jeho nízká odolnost vůči chybám.
Detekce chyb podle teorie kódování…
Při přenosu zakódované informace v prostoru (vysílání a přijímání zprávy) nebo v čase (uložení informace na paměťové médium a její čtení po delší době) může být zpráva různými vnějšími vlivy narušena. To se na úrovni jednotlivých znaků projeví buď tak, že jeden či více znaků zprávy chybí, nebo jsou naopak přidány nové znaky, nebo je počet znaků zachován, ale dojde k záměně některého (některých) z nich za jiný. První typ poruchy, při kterém dochází ke změně počtu znaků (skluz synchronizace), necháme prozatím stranou a budeme se zabývat pouze chybami v blokovém kódu, při kterých je počet znaků zachován.
 Jako detekční kód označujeme takový kód, který objevuje chyby při přenosu. Toho dociluje poměrně jednoduchým způsobem: Je-li vysláno kódové slovo u a přijato nějaké slovo v z množiny Bn, mohou nastat dvě možnosti: buď je přijaté slovo v nekódové, a pak je zřejmé, že toto slovo určitě nebylo vysláno a došlo k chybě (která je tímto objevena), anebo je přijaté slovo v kódové. To ovšem může odpovídat dvěma různým scénářům: buďto je to právě to slovo, které bylo vysláno (to znamená, že přenos proběhl bez chyby), anebo bylo vysláno nějaké jiné kódové slovo, než bylo nakonec přijato (v ≠ u). Protože přijímač nemá žádnou možnost rozeznat, který z těchto dvou scénářů nastal, je poslední eventualita (v ≠ u) nepříznivá − došlo k chybě, kterou kód neobjevil.
Jako detekční kód označujeme takový kód, který objevuje chyby při přenosu. Toho dociluje poměrně jednoduchým způsobem: Je-li vysláno kódové slovo u a přijato nějaké slovo v z množiny Bn, mohou nastat dvě možnosti: buď je přijaté slovo v nekódové, a pak je zřejmé, že toto slovo určitě nebylo vysláno a došlo k chybě (která je tímto objevena), anebo je přijaté slovo v kódové. To ovšem může odpovídat dvěma různým scénářům: buďto je to právě to slovo, které bylo vysláno (to znamená, že přenos proběhl bez chyby), anebo bylo vysláno nějaké jiné kódové slovo, než bylo nakonec přijato (v ≠ u). Protože přijímač nemá žádnou možnost rozeznat, který z těchto dvou scénářů nastal, je poslední eventualita (v ≠ u) nepříznivá − došlo k chybě, kterou kód neobjevil.
Základním parametrem ovlivňujícím schopnost kódu odhalovat chyby je jeho minimální vzdálenost. Definujeme-li Hammingovu vzdálenost dvou slov u a v stejné délky jako počet znaků, ve kterých se slova u a v od sebe liší, pak minimální vzdálenost kódu je nejmenší Hammingova vzdálenost všech dvojic různých kódových slov. Kód s minimální vzdáleností d objevuje všechny t-násobné chyby (tj. nejvýše t chybných znaků ve slově) pro všechna t < d, ale neobjeví všechny d-násobné chyby. Přitom však takový kód může odhalit i některé další chyby. Jaké další chyby kód najde, záleží na jeho konkrétní stavbě. Je-li Hammingova vzdálenost kódu dostatečně velká, může kód některé chyby i opravovat.
Samozřejmě nesmíme schopnost kódu objevovat chyby, popřípadě je i opravovat, chápat doslovně. Pojem „kód objevuje chyby daného typu“ je přesněji definován výrokem „jestliže je vysláno libovolné kódové slovo a při přenosu nastane chyba daného typu, pak je přijaté slovo nekódové“. To vlastně znamená, že je možná existence mechanismu, který pouze na základě přijatého slova určí, zda nastala či nenastala daná chyba. Obdobně to platí i pro schopnost kódu chyby opravovat.
…a v mRNA
Protože existuje 43 = 64 různých kodonů a jen 20 aminokyselin, zdálo by se, že je zde určitá příležitost k vytvoření detekčního kódu. Ve skutečnosti ale všechny kodony (až na tři) kódují aminokyseliny, takže většina aminokyselin je kódována více než jedním kodonem, tj. genetický kód je degenerovaný. Přitom je počet kodonů, které kódují danou aminokyselinu, rozdělen značně nerovnoměrně − zatímco některé aminokyseliny (arginin, leucin a serin) jsou kódovány až šesti různými kodony a většina dalších aminokyselin dvěma nebo čtyřmi kodony, aminokyseliny metionin a tryptofan jsou kódovány každá jediným kodonem AUG a UGG (tab. I). Zbylé tři terminační kodony sice nekódují žádnou aminokyselinu, určují ale konec syntézy proteinového řetězce, proto je nelze považovat za nekódová slova.
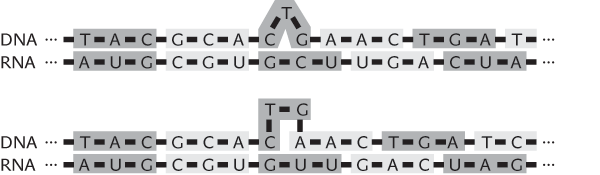 Pro chyby v genetickém kódu používá genetika vlastní terminologii. Chyba v genetickém kódu se nazývá mutace, jednoduchá chyba (kdy je chybně umístěná právě jedna báze) je bodová mutace. Přidání jedné či více bází je inzerce, pokud naopak báze chybí, jde o deleci. Inzerce a delece odpovídají skluzu synchronizace.
Pro chyby v genetickém kódu používá genetika vlastní terminologii. Chyba v genetickém kódu se nazývá mutace, jednoduchá chyba (kdy je chybně umístěná právě jedna báze) je bodová mutace. Přidání jedné či více bází je inzerce, pokud naopak báze chybí, jde o deleci. Inzerce a delece odpovídají skluzu synchronizace.
Jak je vidět z tab. I, samotný genetický kód pro translaci (na mRNA) nemá žádnou schopnost detekce chyb. To matematika nepřekvapí, protože jeho minimální vzdálenost je pouze 1 (kód totiž obsahuje dvojice kodonů, které se liší jen v jediné bázi a přitom kódují stejnou aminokyselinu). Z pohledu teorie kódování tedy genetický kód rozhodně není kódem detekčním.
Degenerace genetického kódu však přece jen přináší trochu odolnosti vůči chybám. Dva nebo čtyři kodony pro určitou aminokyselinu se typicky liší jen na třetí pozici a záměna v ní tedy sice změní kód, ale nevede ke změně aminokyseliny. Například kodon GGU (kódující aminokyselinu glycin) toleruje jakoukoliv bodovou mutaci na třetí pozici, protože kodony GGC, GGA a GGG také kódují glycin. (Arginin a leucin navíc tolerují i některé změny prvního nukleotidu.) Takovým mutacím se říká tiché mutace.
Genetický kód na dvouvláknové DNA
Genetický kód v dvouvláknové DNA slouží k dlouhodobému (přes generace) uchování genetické informace. Abychom ho odlišili od genetického kódu v mRNA, který je používán pro translaci, budeme jej nazývat DNA-genetický kód.
Každý nukleotid se páruje se svým protějškem (komplementární bází) na protějším vláknu. Triplety na dvouvláknové DNA proto můžeme ztotožnit se slovy o 6 nukleotidech. DNA-genetický kód je pak kvaternární blokový (6,3)-kód s kódovou abecedou {A, C, G, T}. Jeho kódové slovo má tři informační znaky na kódujícím vlákně a tři kontrolní znaky na vlákně komplementárním. Informační poměr DNA-genetického kódu je tedy 3/(3+3) = 1/2.
Protože dvě různá kódová slova DNA-genetického kódu se liší nejméně dvěma znaky (dvojicí protějších nukleotidů) a existuje dvojice kódových slov, která se liší právě dvěma znaky, je minimální vzdálenost DNA-genetického kódu rovna 2. Odtud rovnou plyne, že DNA-genetický kód detekuje všechny jednoduché chyby (to znamená mutace v jednom nukleotidu). Ve skutečnosti je ale schopný odhalit mnohem větší množinu chyb, například všechny dvojnásobné a trojnásobné chyby, které mají všechny chybné znaky na stejném vlákně nebo všechny chyby, kde alespoň jeden pár na protějších pozicích netvoří komplementární báze.
Samoopravné schopnosti DNA‑genetického kódu
Samotná teorie kódování neslibuje žádné samoopravné schopnosti DNA-genetického kódu. Na to, aby byl schopen opravit alespoň jednoduché chyby, by jeho minimální vzdálenost musela být nejméně 3. Příroda si však dokázala poradit jinak.
Transkripce a replikace jsou velmi přesné mechanismy. Při transkripci se objeví přibližně jen jedna chyba za 104 bází. Chybovost translace není příliš podstatná, protože jedna vadná molekula proteinu obvykle nemůže napáchat velkou škodu. Největší dopad na správnou funkci buňky a jejích potomků může mít chyba při replikaci. Proto je její přesnost mnohem vyšší, než u transkripce.
Již do samotného procesu replikace jsou zabudovány kontrolní a opravné mechanismy. Pokaždé, když je do nově vznikajícího vlákna DNA přidáván nový nukleotid, kontroluje se správnost spárování nukleotidu předcházejícího. Pokud není párování v pořádku, vhodné enzymy chybný nukleotid ihned odstraní a nahradí jej správným. Díky tomuto kontrolnímu čtení (proofreading) je chybovost replikace (pravděpodobnost jednoduché chyby) řádově 10−7.
 Bezprostředně po ukončení replikace části řetězce probíhá další kontrola správného párování bází (mismatch repair). Přitom dokáže enzymatický aparát rozeznat původní řetězec DNA od nově syntetizovaného vlákna a chybně spárovaný nukleotid na novém vlákně nahradit správným. V důsledku těchto oprav je výsledná chybovost replikace pouhých 10−9. Tak malá chybovost je nesmírně důležitá, vždyť řada zákeřných nemocí (např. srpková anémie) vzniká změnou jen jediného písmene genetické abecedy.
Bezprostředně po ukončení replikace části řetězce probíhá další kontrola správného párování bází (mismatch repair). Přitom dokáže enzymatický aparát rozeznat původní řetězec DNA od nově syntetizovaného vlákna a chybně spárovaný nukleotid na novém vlákně nahradit správným. V důsledku těchto oprav je výsledná chybovost replikace pouhých 10−9. Tak malá chybovost je nesmírně důležitá, vždyť řada zákeřných nemocí (např. srpková anémie) vzniká změnou jen jediného písmene genetické abecedy.
Mnohem častěji než k chybě při replikaci dojde k poškození nukleotidu vnějšími vlivy, jako je například ionizující záření nebo různé silně reaktivní chemické látky. Místo jedné ze čtyř základních bází se pak v DNA mohou vyskytnout jejich různé modifikace. Kódová abeceda je tedy vlastně {A, C, G, T, Q1, Q2, Q3, …}, kde Qi jsou tyto modifikované báze. Například guanin může být změněn na 6-O-metylguanin, který se páruje s thyminem místo s cytosinem. Protože jsou to evidentně chybné znaky, detekuje genetický kód všechny chyby, kde je alespoň jedno Qi. DNA-genetický kód má navíc i schopnost opravit všechny chyby, kde se nevyskytují dvě Qi proti sobě.
Mechanismy oprav DNA
Kromě oprav, které probíhají již v průběhu replikace, má buňka k dispozici řadu dalších postupů opravy poškozené DNA. Nejjednodušší možností opravy je přímé nahrazení některých změněných nukleotidů správnými. Opravný mechanismus k tomu nepotřebuje žádný vzor, protože určitá modifikovaná báze Qi mohla vzniknout pouze z konkrétní báze správné.
Druhým přístupem je oprava poškozeného úseku dvouvláknové DNA pomocí nepoškozeného druhého vlákna. Enzymatický aparát buňky najde vadný nukleotid (jeden ze znaků Qi), vystřihne ho i s několika sousedícími nukleotidy, odbourá je a chybějící úsek nahradí záplatou syntetizovanou podle nepoškozeného vlákna.
Podobný, ale poněkud složitější je mechanismus rekombinantní reparace, při které proběhne oprava podle sesterské molekuly DNA. (Každá nepohlavní buňka totiž obsahuje dvě kopie každé molekuly DNA − od každého rodiče jednu.)
Bakterie mají jako poslední záchranu ještě jeden mechanismus, takzvanou SOS syntézu. Při ní se silně poškozený úsek DNA (ve kterém mohou být porušena i obě vlákna DNA) přemostí víceméně náhodně zvolenými nukleotidy. Tento proces je pochopitelně značně nepřesný a genetická informace z takto opraveného úseku je pravděpodobně ztracena. Jeho přínos je v tom, že obnoví integritu DNA, která se pak může dále replikovat. S trochou štěstí ztracený úsek nekódoval nic opravdu důležitého, popřípadě jej může bakterie získat od některé sousedky. Tuto schopnost vyměňovat si DNA s jinými jedinci některé bakterie mají.
Proč má DNA tři terminační triplety?
Začněme ilustračním příkladem. Uvažujme sekvenci bází
…AGCGUUACCAU…
a položme si otázku, jakému řetězci aminokyselin odpovídá? Podle tab. I to může být:
…+ serin + valin + treonin + (AU)… nebo
…(A) + alanin + leucin + prolin + (U)… nebo
…(AG) + arginin + tyrosin + histidin +…,
což jsou zcela odlišné trojice aminokyselin. Který řetězec se má tedy syntetizovat?
Genetický kód DNA má jediný iniciační triplet ATG, který určuje počátek syntézy a zároveň kóduje aminokyselinu metionin. Na jednořetězcové molekule RNA tento triplet odpovídá AUG, protože thymin je nahrazen uracilem. Každý proteinový řetězec tak nejprve začíná aminokyselinou metioninem (která pak obvykle bývá z proteinu odstraněna specifickou proteázou), neboť je kódován iniciačním tripletem AUG. Po něm na řetězci RNA následuje poměrně dlouhá sekvence definující samotný protein, která má v typickém případě tisíce kodonů a neobsahuje (kromě svého konce) žádný terminační kodon UAA, UAG či UGA.
Protože jednotlivé triplety nejsou na vlákně DNA nijak odděleny, mohou se při přepisu do mRNA nesprávně napojit na trojici posunutou o jeden nukleotid vpravo či vlevo, což by vedlo k nesprávné syntéze. Dochází k tzv. skluzu synchronizace (obr. 2). Z tohoto pohledu se ukazuje jako obzvláště výhodné, že ve standardním genetickém kódu existují hned tři terminační (zastavovací) triplety. Nesprávně syntetizovaný protein pak brzy ukončí právě jeden ze tří terminačních tripletů posunutý o jeden nukleotid vpravo či vlevo (obr. 3).
To, že existuje jen jeden iniciační kodon AUG, má také jistou evoluční výhodu, protože se minimalizuje počet míst, odkud se čte informace, i když třeba chybně. Povšimněme si dále, že cyklickou permutací iniciačního tripletu AUG dostaneme terminační triplet UGA. Za terminačními triplety je většinou spíše náhodná sekvence nukleotidů než nějaký gen. V ní brzy dospějeme k nějakému terminačnímu tripletu, i když budeme číst posunuti o jeden nukleotid.
Proč překřížení (crossing-over) chromozomů nerespektuje hranice jednotlivých genů?
Přibližně 95 % informace, která je obsažena v DNA, se kódování neúčastní, i když v dávných dobách nějaký význam mohla mít. K překřížení chromozomů tak většinou dochází mimo geny. V DNA existují úseky obsahující až 100 000 párů bází, které se do RNA vůbec nepřepisují. Pokud přesto dojde k překřížení uvnitř nějakého genu (navíc bez ohledu na triplety), jedná se vlastně o mutaci, která ale může ve zcela výjimečných případech vést i k vylepšení nějaké vlastnosti.
Poděkování: Článek byl podpořen projektem RVO 67985840 a granty IAA 100190803 GA AV ČR a P205/12/P392 GA ČR.
Literatura
Alberts B. a kol.: Základy buněčné biologie, Espero Publishing, Ústí nad Labem 1998.
Crick F. H. C., Griffith J. S., Orgel L. E.: Codes without commas, Proc. Natl. Acad. Sci. USA 43, 416−421, 1957.
Gamow G.: Possible relation between deoxyribonucleic acid and the protein structures, Nature 173, 318, 1954.
Nirenberg M. W., Matthaei J. H.: The dependence of cell-free protein synthesis in E. coli upon naturally occurring or synthetic polyribonucleotides, Proc. Natl. Acad. Sci. USA 47, 1588−1602, 1961.
Ke stažení
 článek ve formátu pdf [358,02 kB]
článek ve formátu pdf [358,02 kB]
O autorech
Doporučujeme

Když bahno teče jako ledovec

Ideologie v mapách, mapy v rukách ideologů 
