









Zviditelnění významů
| 12. 2. 2009Všechno ve vědě je podrobováno kritice. Stalo se to i modelu textové struktury, který je založen na Menzerathově-Altmannově (MA) zákonu. Pochybnosti by neměly být ani v populárněvědném článku zamlčeny. Tím spíš, že jde o věci, které po tisíciletí zůstávaly nerozluštěny, ačkoliv je to něco, co nosíme uvnitř ve svých hlavách.
Existují vědecké obory, které jsou bezprostředně soustředěny na tajemství lidského nitra. Především psychologie a psychiatrie analyzují texty v přirozeném jazyce. Texty do jejich zkumavek vychrchlávají zkoumaná nitra a těmto oborům nezbývá než analyzovat jejich struktury intuitivně, bez konfrontace s nějakým racionálně formulovaným jazykovým modelem. Lingvistika dluží těmto i dalším oborům základ k použitelné racionální analýze, protože při zkoumání jazyka se zarazila u věty jako u nejvyšší jazykové úrovně. Větu velmi přesvědčivě a důkladně rozebrala na jednotky od hlásek až po syntaktické konstrukce, ale pak hned skočila k pojmu „jazyk“. Tím vznikl dojem, že jazyk je věta, což není.
Co je vlastně text
I ve vědě se stane, že něco je bráno jako samozřejmost. Navíc s definicemi bývají formálně logické potíže, všechno nelze definovat s naprostou přesností. Dokonce se už přestalo říkat, že věda je úsilím o přesnost; spíš se klade důraz na přibližnost, podobnost, analogii a ekvivalenci. Textová lingvistika při pokusech o formulaci MA modelu zacházela s pojmem „text“ jako s pojmem axiomatickým, u něhož každý ví, co to přibližně je. Chápala text jako nějaké pozorované, přirozené, lidským mozkem protažené seřazení vět a jejich struktur. Je zcela samozřejmé položit otázku: Má každý text nějaký začátek a konec? Ano, může mít, ale co když je k dispozici třeba jen několik vytržených stránek z deníku důležité osoby, zájemci se na ně vrhnou a čtou je jako text, rozumějí jim, protože též oni je protahují svými mozky a v činnosti tak jsou mechanismy, které zpracovávají sémantické informace jako v přirozených situacích jazykové komunikace. Je to pro ně text.Když spisovatel píše knihu a je tak pilný, jako byl třeba Tolstoj, i kdyby plynule navazoval na dříve napsané části svého textu, sémantická dynamika mozku může podvědomě vytvořit předěl, který nemusí být vyznačen graficky. Jinak samozřejmě text je vymezen v přirozeném procesu komunikace: spisovatel člení svůj text na části, kapitoly, odstavce; rozhovor dvou sousedů na pavlači může být přerušen příchodem dalšího souseda atd. Na rozdíl od vymezení textu vnějšími okolnostmi je jeho sémantické vnitřní členění dáno splněním kritérií MA modelu. Kdybychom to měli vyslovit hrubě populárně, asi bychom řekli: Řečový útvar vykazující negativní hodnotu parametru MA zákona je text ve smyslu textové lingvistiky. Ta negativní hodnota je matematickým ekvivalentem slovní formulace MA zákona („čím delší jazykový konstrukt, tím kratší v průměru jeho konstituenty“). Takže textem je třeba jeden odstavec ze Švejka, ale i celá Vojna a mír. Pokud provádíme analýzu, měl by ten odstavec být dostatečně dlouhý, abychom získali měřitelná data, a u Tolstého díla naopak bychom měli respektovat nejen fakt, že je složeno z odstavců, kapitol, částí a knih, ale že má i své vnitřní členění dané sémantickými strukturami. Z toho plyne, že text je pro analýzu souvislost jazykových struktur (či systémů). Souvislost struktur je předmětem analýzy jazykového kódu. Toho kódu, který odkazuje k systému významů v hlavě produktora (spisovatele) nebo recipienta (čtenáře) textu.
Jistý obratný technik (jaký lingvista?) našel na internetu údaje získané z anglického textu Bílé velryby Hermana Melvilla, vložil je do počítače, a ejhle! Parametr MA zákona, který má být negativní, je mírně nad nulou. Kdybychom vzali kteroukoliv souvislou část tohoto románu, samozřejmě zjistíme o tomto parametru něco opačného. Osobní zkušenost s analýzou rostoucího (v daném případě tureckého) textu ukázala, jak se s narůstáním díla po kapitolách mění distribuce lexikálních jednotek, a tím i chování sémantických konstruktů.
Při analýze bychom měli mít na paměti nezbytnost interpretace textu, tj. aby k určité mimojazykové skutečnosti vždy odkazovala jedna a táž lexikální jednotka; například hrdina románu by neměl být v analyzovaném textu reprezentován různými jmény, přezdívkami či referenčními prostředky. Když operujeme se slovy, měli bychom také dobře zvážit, co je a co není slovo. Některé frekvenční analýzy na internetu tvrdí, že nejfrekventovanějším „slovem“ angličtiny je člen the. Můžeme vést veleučenou při, zdali je to slovo, nebo gramatický morf. Při analýze bychom též měli mít na mysli, že nám nejde o nějaké hýčkání parametrů, nejde nám o distribuci jednotek kódu (i když by to mohlo mít smysl pro nějaké účely, třeba výukové či tiskařské). Ve skutečnosti v lingvistice šplháme od věty nahoru k jazyku přes sémantické konstrukty textu a samotný text, abychom se dostali k vrcholu.
Realita struktury a imaginární stíny
Zabýváme se velmi složitým systémem, jehož výstupem je jazykový produkt. Přehrabovat se v takovém systému a pokusit se najít onu nit, na níž je celý tento systém zavěšen, často vyžaduje redukci, a tedy i zvláštní argumentaci.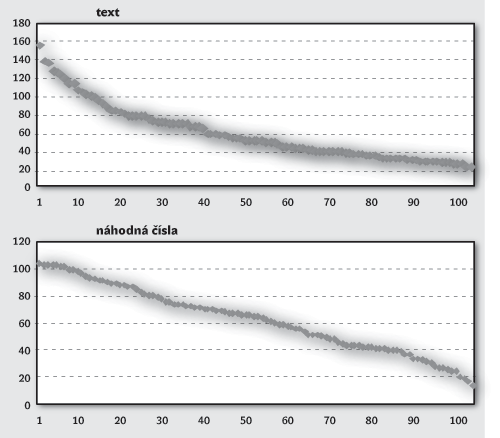 Autor jistého kritického stanoviska se jmenuje E. S. Wheeler. 1) I když tato kritika není zaměřena přímo na MA zákon ani na jeho aplikaci na sémantickou strukturu textu, je chytrá a končí výzvou, kterou by bylo dobré uposlechnout.
Autor jistého kritického stanoviska se jmenuje E. S. Wheeler. 1) I když tato kritika není zaměřena přímo na MA zákon ani na jeho aplikaci na sémantickou strukturu textu, je chytrá a končí výzvou, kterou by bylo dobré uposlechnout.
Modelová situace, o kterou v daném případě jde, je následující: Mysleme si proces, při němž se krájí dort na náhodně velké kousky; prvních několik kousků může být velkých, ale když se po jejich odkrojení koláč hodně zmenší, další zájemci mohou obdržet jen menší a menší kousky. Je zřejmé, že tato situace na textovou strukturu příliš nesedí. Podle autora testovací metody založené na použití náhodných dat pomůžou uvidět, zdali pozorovaná vlastnost reality nebyla realitě vnucena aplikovanou metodou analýzy. Dosadit místo pozorovaných náhodná čísla může být užitečné.
Na základě tohoto doporučení jsme s textem provedli následující pokus: Mějme dvě osudí, v každém z nich jsou uložena náhodná čísla. Vylosujme z prvého osudí hodnotu x jako velikost konstruktu. Pak losujme z druhého osudí xkrát a z vylosovaných čísel vypočítejme průměr y. Místo osudí byly samozřejmě použity tabulky náhodných čísel. Při dostatečném počtu opakování tohoto pokusu jsme pokaždé dostali hodnoty y, které neklesaly, nýbrž rostly s rostoucím x. To je přesná náhodná paralela k MA zákonu, čili můžeme usoudit, že tento zákon zobrazuje reálnou situaci v sémantickém systému textu.
Porovnali jsme výsledky náhodného pokusu s daty získanými z pozorovaného (tureckého) textu; z jistého výzkumného důvodu byla tentokrát délka vět zobrazena v počtu hlásek. Věty jsou seřazeny do Zipfova pořadí, takže na horizontální ose (viz obrázek 1a a 1b) jsou jednotlivé věty podle velikosti od nejvyšší do nejnižší, na vertikální ose je délka věty v počtu hlásek. Sémantická struktura textu je tu ohlodána na nejvyšší míru. Mezi hláskou případně chápanou jako konstituent a větou jako konstrukt je veliká vzdálenost dvou nebo tří jazykových úrovní, do nichž do každé vstupují náhodné vlivy osobitého charakteru, které mohou působení MA zákona deformovat. Co nejvíc jsme se snažili vnutit tomuto experimentu náhodu, a tak jsme omezili vylosovanou délku vět do intervalu, jaký byl pozorován ve srovnávaném textu, tj. větší náhodná čísla jsme nebrali v úvahu.
Z obrázků dvou křivek je však zřetelný rozdíl mezi oběma přístupy. Myslím, že tento pokus byl uspořádán podle Popperova požadavku na testování vědeckých hypotéz; podle slavného epistemologa má být pokus vždy organizován tak, aby výsledek byl „na ostří nože“. Lze k němu dodat, že byl doplněn některými dalšími testy, které mohou snad kritiky přesvědčit, že při zobrazování sémantické struktury textu nevidíme jen nějaké imaginární stíny. Prohnutí horní křivky na obrázku je elegantní a půvabné.
Poznámky
Ke stažení
 článek ve formátu pdf [602,56 kB]
článek ve formátu pdf [602,56 kB]
Doporučujeme

Když bahno teče jako ledovec

Ideologie v mapách, mapy v rukách ideologů 
