









Lingvistika na Matematicko-fyzikální fakultě?
| 6. 9. 2012Otázka položená v nadpisu tohoto příspěvku je dnes již otázkou jen pro nezasvěcené. Počítačová a formální lingvistika mají na Matematicko- fyzikální fakultě již dlouhou tradici: první – ještě ne zcela úředně emancipovaný – útvar zabývající se touto problematikou vznikl na této fakultě v roce 1962 pod vedením Petra Sgalla. V současné době, kdy na fakultě existuje sekce informatiky jako jedna ze tří základních složek fakulty, je to vzhledem k bezbřehým potřebám automatického zpracování jazyka otázka téměř nemístná: v současném Ústavu formální a aplikované lingvistiky (dále ÚFAL) pracuje na aplikovaných i teoretických úlohách spojených s přirozeným jazykem desetkrát víc informatiků, matematiků a lingvistů než před 50 lety, a to za úplně jiných technických i společenských podmínek.
Počítačová lingvistika
 Matematická nebo také počítačová, komputační lingvistika je propojením oblastí ze dvou různých světů – explicitního a formálního světa počítačů a matematiky a světa humanitního, kde se tradičně pro zkoumání lidského, přirozeného jazyka používají metody zcela jiné. Je proto přirozené ptát se, jak je vůbec možné, že takové spojení vzniklo – a zda vlastně přirozený jazyk explicitními metodami vůbec zkoumat lze. Odpověď na otázku „jestli vůbec“, kterou jsme výše položili, je vázána na otázku, jestli vůbec a proč je takový interdisciplinární výzkum dobrý.
Matematická nebo také počítačová, komputační lingvistika je propojením oblastí ze dvou různých světů – explicitního a formálního světa počítačů a matematiky a světa humanitního, kde se tradičně pro zkoumání lidského, přirozeného jazyka používají metody zcela jiné. Je proto přirozené ptát se, jak je vůbec možné, že takové spojení vzniklo – a zda vlastně přirozený jazyk explicitními metodami vůbec zkoumat lze. Odpověď na otázku „jestli vůbec“, kterou jsme výše položili, je vázána na otázku, jestli vůbec a proč je takový interdisciplinární výzkum dobrý.
Odpověď na otázku „proč“ je vcelku jednoduchá. Chceme-li se přiblížit ke skutečné „umělé inteligenci“ – ať už ve smyslu Čapkových robotů, nebo v podobě mnohem jednodušší, např. pro porozumění mluveným pokynům k ovládání autorádia či mobilního telefonu nebo jako virtuálního pomocníka při psaní gramaticky správných vět v nějakém přirozeném jazyce na počítači – musíme vytvořit takový systém – řekněme to s jistou nadsázkou – „umělé inteligence“, který rozumí (alespoň do určité míry) danému přirozenému jazyku a umí v některých aplikacích i sám v tomto jazyce správně tvořit jednotlivé věty a jejich posloupnosti.
 Mluvíme-li o systému, který má rozumět přirozenému jazyku, můžeme stejně tak dobře říci, že požadujeme, aby počítač uměl zpracovávat přirozený jazyk. Spojení počítačové zpracování přirozeného jazyka (synonymum počítačové lingvistiky) je doslovným překladem anglického termínu natural language processing.
Mluvíme-li o systému, který má rozumět přirozenému jazyku, můžeme stejně tak dobře říci, že požadujeme, aby počítač uměl zpracovávat přirozený jazyk. Spojení počítačové zpracování přirozeného jazyka (synonymum počítačové lingvistiky) je doslovným překladem anglického termínu natural language processing.
Pokud počítač porozumí (tj. zpracuje přirozený jazyk), pak odhalí např. chybu v pádu po předložce, která se s příslušným pádem nepojí (*na tunelem), odhalí ji mylně ovšem i ve spojení na nedokončeným tunelem projíždějící auto se vyhláška vztahuje; odhalí chybu ve shodě podmětu s přísudkem (*Sportovci zvítězily.), ale jako chybu nesprávně označí -y i ve slově házely v posloupnosti vět Dívky křičely. Sportovci házely plyšáky a rozhodčím shnilá rajčata, kde shoda podmětu s přísudkem v druhé z vět plyne z předcházející věty. Z věty Přijela policie, evakuovala téměř tisíc přítomných lidí a bezpečně nastraženou bombu odpálila. (MF Dnes, 1997) čtenář, nikoli však počítač pochopí, že se mluví spíše o bezpečném odpálení bomby, nikoli o jejím bezpečném nastražení. Při interpretaci odkazovacích zájmen v posloupnosti Ráno jsem přijel pro kytici růží pro nevěstu. Nelíbila se mi, představoval jsem si ji jinak (z rozhovoru se známým politikem) čtenář vyloučí jeden méně společensky přijatelný, ale gramaticky korektní výklad, kdy by nevyjádřený podmět v první části druhé věty a odkazovací zájmeno ji vztáhl k substantivu nevěsta.
Z uvedených příkladů je vidět, že schopnost počítače „porozumět“ je větší či menší, někdy téměř nemožná.
Formální popis přirozeného jazyka
Pro zajištění alespoň takového „porozumění“ přirozenému jazyku, které lze od počítače požadovat, musí existovat aparát (schéma), kterým bude jazyk explicitně popsán. Běžně užívané slovníky a gramatiky nebo učebnice jazyků poskytují nám, lidem, spoustu užitečných informací, ale přitom implicitně předpokládají, že jsme myslící bytosti, které navíc ovládají alespoň jeden přirozený jazyk a dokážou tuto znalost aplikovat pomocí analogie i na jazyk, který se učíme nebo v němž se zdokonalujeme (jde-li o náš jazyk mateřský). Takové gramatiky a slovníky, i když mohou být samozřejmě převedeny do elektronické podoby, nejsou ovšem pro počítačové zpracování moc platné, počítač si neumí „domýšlet“ nevyřčené tak, jako to dovede člověk. Pro počítačové zpracování je třeba jazyk uchopit metodami matematickými a vytvořit jeho formální popis.
Velkým impulsem ke zkoumání přirozeného jazyka formálními prostředky byly práce Noama Chomského (dnes známého spíše jeho politickými názory), pro lingvistiku byla podnětná zejména jeho monografie z roku 1957 „Syntactic Structures“, kde vyslovil hypotézu, že jazyk lze popsat formální gramatikou určitého typu, a tuto gramatiku také přesně popsal. Je nutné dodat, že i když dnes už víme, že takto se jazyk ve své úplnosti popsat nedá, Chomského práce měly velký význam nejen v lingvistice, ale zejména v informatice, kde jsou základem pro definici a analýzu formálních jazyků a dodnes je systém typů těchto jazyků nazýván Chomského hierarchií.
 Odpověď na otázku „jestli vůbec“ je vázána na konkrétní případy propojení lingvistiky a informatiky. Stojí jistě za úvahu, zda efekt softwarových produktů založených na různých formách zpracování přirozeného jazyka je úměrný množství námahy potřebné pro jeho vývoj. Toto hledisko (snížení lidských i hmotných zdrojů) vedlo v devadesátých letech v počítačové lingvistice k jistému průlomu – k masivnímu nasazení statistických metod. Zatímco v první polovině 20. století to byli převážně lingvisté, z jejichž strany vycházela iniciativa k výzkumu počítačového zpracování jazyka, ke konci 20. století to byli překvapivě převážně matematici, statistici, fyzici a informatici, kdo přicházeli s novými impulsy. Vyspělé počítačové technologie poskytují základnu i pro strojové učení. Při strojovém učení se totiž počítačový program učí z různě rozsáhlých souborů jazykových dat, textových i mluvených, aby následně mohl ne zcela nahradit, ale částečně zastoupit člověka v automatizaci činností svázaných s přirozeným jazykem.
Odpověď na otázku „jestli vůbec“ je vázána na konkrétní případy propojení lingvistiky a informatiky. Stojí jistě za úvahu, zda efekt softwarových produktů založených na různých formách zpracování přirozeného jazyka je úměrný množství námahy potřebné pro jeho vývoj. Toto hledisko (snížení lidských i hmotných zdrojů) vedlo v devadesátých letech v počítačové lingvistice k jistému průlomu – k masivnímu nasazení statistických metod. Zatímco v první polovině 20. století to byli převážně lingvisté, z jejichž strany vycházela iniciativa k výzkumu počítačového zpracování jazyka, ke konci 20. století to byli překvapivě převážně matematici, statistici, fyzici a informatici, kdo přicházeli s novými impulsy. Vyspělé počítačové technologie poskytují základnu i pro strojové učení. Při strojovém učení se totiž počítačový program učí z různě rozsáhlých souborů jazykových dat, textových i mluvených, aby následně mohl ne zcela nahradit, ale částečně zastoupit člověka v automatizaci činností svázaných s přirozeným jazykem.
Pohled do historie kvantitativního zkoumání češtiny
Historicky viděno, nejsou kvantitativní zkoumání v lingvistice úplně nová: na přelomu 19. a 20. století začala do lingvistiky pronikat statistika. Zkoumání přirozeného jazyka mělo v té době charakter popisný a soustředilo se kolem pojmu frekvence a frekvenční analýza. Šlo o sledování frekvence (četnosti výskytu) jednotek na všech rovinách popisu přirozeného jazyka, tj. např. četnost fonémů, hlásek, slov, slovních druhů, pádů, větných členů atd. Tímto kvantitativním výzkumem se ustavil nový podobor lingvistiky, lingvistika kvantitativní.
Pohled do historie české lingvistiky dokládá, že první aplikace statistických kvantitativních metod při studiu jazyka sahá až k diskusi o pravosti Rukopisu zelenohorského koncem 19. století, kdy A. Seyler (1849–1891) na základě iniciativy T. G. Masaryka využil pravděpodobnostní počet k tomu, aby se vyloučila náhodnost výskytu některých jazykových jevů. V té době to byl pokus ojedinělý a nesetkal se s patřičným ohlasem, ale už začátkem 20. století zakladatel Pražského lingvistického kroužku Vilém Mathesius v přednášce o potenciálnosti jazykových jevů (1911) ukazuje, že ke studiu jazykových jevů jako stabilních nebo potenciálních mohou přispět i statistické údaje. V Pražském kroužku se otázkami frekvence jazykových jevů zabýval ještě před válkou profesor Bohumil Trnka v souvislosti s těsnopisem. A právě péčí profesora Trnky vyšla roku 1950 v Belgii také vůbec první bibliografie kvantitativní lingvistiky.
Na přelomu dvacátých a třicátých let se americký psycholog a lingvista G. K. Zipf věnoval kvantitativní analýze jazyka a ve formě tzv. Zipfových zákonů zformuloval tvrzení o závislosti počtu různých slov v textu a frekvence jejich výskytu, o poměru frekvencí slov a počtu různých slov s touto frekvencí a o závislosti frekvence slova a počtu jeho významů. I druhá světová válka hrála svoji roli. Ví se, že řada spojeneckých úspěchů je zásluhou muže jménem Alan Turing. Tento geniální matematik po roce 1943 pracoval pro britskou zpravodajskou službu v pověstném Bletchley Park, kde za pomoci kolegů sestrojil tzv. „bombu“ – stroj na dešifrování německých příkazů nejvyššího velení, zakódovaných pomocí německého šifrovacího stroje Enigma. Jak známo, i ve válce jsou zprávy a příkazy předávány přirozeným jazykem – a právě některých statistických vlastností přirozeného jazyka Turing použil k rozbití německého kódu.
Na přelomu čtyřicátých a padesátých let v souvislosti se vznikem kybernetiky se v rámci matematiky zformovaly dva nové vědní obory – teorie komunikace a teorie informace. Oba dva obory mají k sobě velmi blízko, zabývají se přenosem informace. Základní myšlenku zformuloval Američan Claude Shannon. V knize o teorii informace (společně s Warrenem Weaverem, The Mathematical Theory of Communication, 1949) teoreticky popsal a zobecnil způsoby přenosu informace, přičemž se zabýval zejména tím, jak tato informace může být přenosem zkreslena a na přijímacím místě opět (pokud možno s minimální chybou) zrekonstruována. Zavedl také důležitý pojem entropie v teorii informace.
Dvě poslední zmíněné události, ke kterým došlo ještě před publikací Chomského Syntaktických struktur (viz výše), přinesly nový statistický impuls lingvistice. Na začátku padesátých let ovlivnily vývoj tehdejší americké experimenty se zpracováním jazyka – zejména s tzv. strojovým překladem, tj. automatickým překladem z jednoho jazyka do druhého (viz zde příspěvek O. Bojara na s. 488). Tehdy šlo – jak jinak – o překlad z ruštiny do angličtiny. Na základě Turingových úspěchů s prolomením šifer a kódů a na základě Shannonovy teorie informace lze totiž problém překladu formulovat jako problém šifrování (či spíše dešifrování) – věta v ruštině se považuje za šifrovanou větu v angličtině, a cílem překladu je vlastně tedy dešifrování původní (zde anglické) věty. V padesátých letech minulého století byly ovšem možnosti počítačů v porovnání s bohatostí přirozeného jazyka velmi omezené, a proto tyto pokusy nevedly k plnému úspěchu. Navíc právě v druhé polovině padesátých let téměř všichni ve vznikajícím odvětví lingvistiky, které se zabývalo formálním popisem jazyka, pracovali pod vlivem Chomského modelů frázových gramatik založených na pravidlech; Chomsky ostatně velmi striktně odmítl možnost jakéhokoli statistického pohledu na přirozený jazyk. Tento nepřátelský postoj se podařilo prolomit až na počátku devadesátých let.
V těch letech se stal zcela dominantním směr, který přidává k matematickým a formálním postupům, dosud v lingvistice používaným, statistiku už ne jako věc popisnou, ale jako metodu modelování jazykových jevů. Tyto statistické metody (viz rámeček) v počítačové lingvistice posunuly počítačovou lingvistiku velmi výrazně k vědám experimentálním, a definitivně tak skončilo konsensuální pojetí některých směrů vývoje tohoto oboru. Jakými metodami se tedy dnes postupuje? Nejhezčí analogie je, kupodivu, s astronomií: pokud si vybavíme vývoj astronomie od středověku, snažila se vysvětlit postavení hvězd na obloze tak, že vytvářela matematické modely a porovnávala je s naměřenými daty (tj. s polohou hvězd na obloze). Postupně tak astronomie došla k jednodušším a jednodušším (a adekvátnějším!) modelům vesmíru. V přírodních vědách se jedná o postup zcela obvyklý. Jak však v lingvistice měříme jazyk? Na první pohled věc prakticky nemožná. Avšak po desetiletích vývoje formálních prostředků popisu jazyka a jejich osvojení experty-lingvisty je možno k takovému „měření“ tyto experty využít – dáme-li totiž velké množství textů nebo promluv analyzovat za pomoci počítačových nástrojů jazykovým expertům podle předem zadaného scénáře, dostaneme ono potřebné „měření“ – samozřejmě v symbolickém smyslu. Tato „jazyková data“ pak lze použít pro automatické zjištění parametrů známými nebo modifikovanými metodami strojového učení nebo i jednoduššího přímého statistického modelování.
Již jsme se zmínili, že na počátku devadesátých let byly překročeny hranice předsudků vůči statistickému modelování v lingvistice a došlo k jeho dominantnímu rozmachu. Tento jev se okamžitě promítl i do skladby příspěvků na konferencích. Drtivá většina příspěvků byla a stále je tomuto proudu věnována.
Korpusy (nejen) pro statistiku
Matematická statistika pracuje s empirickými znalostmi formou pozorování souboru dat. Soubory jazykových dat mají v počítačové lingvistice různou povahu: jsou to korpusy jednojazyčné nebo paralelní, synchronní nebo diachronní, korpusy jazyka psaného nebo mluveného, korpusy školské nebo jinak specializované.
Jednojazyčný korpus je souborem textů či promluv v jednom jazyce. Pro češtinu je největším textovým korpusem Český národní korpus (vyvíjený v Ústavu Českého národního korpusu na FF UK s přispěním dalších institucí); v současné době pokrývá ve všech svých složkách 1300 milionů slov. Máme-li se dovědět o daném jazyce (nebo o jazyce vůbec) co nejvíc a efektivně tuto informaci využít pro počítačové zpracování (tedy i pro statistické modelování), je třeba shromážděná data (korpusy) obohatit jejich anotováním, tj. doplňováním hodnot gramatických či jiných (např. lexikálně sémantických) kategorií jednotlivým prvkům věty (ať již na úrovni řetězu slov nebo syntaktických struktur). Tento názor je dnes už doložen existencí či vývojem anotovaných korpusů řady jazyků (např. Penn Treebank s odvozenými korpusy, jako je PropBank nebo Penn Discourse Treebank pro angličtinu, Tiger pro němčinu a v neposlední řadě i rodina českých anotovaných korpusů, viz dále). Podmínkou takového zhodnocení ovšem je, že pro anotování je vytvořen dobře promyšlený konzistentní scénář založený na propracované lingvistické teorii.
Konstatujeme, že anotování jazykového korpusu není samoúčelné, ale vedle toho, že poskytuje jedinečnou příležitost, jak ověřovat lingvistickou teorii, umožňuje především vypracovat procedury, které se na základě dat vytvořených experty (lingvisty, ale i za pomoci přívětivého počítačového prostředí) mohou „učit“ a „naučit“ analyzovat (zpracovávat) běžný text (neznámý, tedy systémem dosud neviděný), a tak rozšiřovat procedury pro porozumění textu daného jazyka.
Pražské anotované korpusy
Rodina tzv. pražských anotovaných korpusů je díky aktivitě ÚFAL dosti početná. Pokud máme uvést pouze jména těch nejrozsáhlejších, tak jmenujme jednojazyčný Pražský závislostní korpus (PDT), Pražský arabský závislostní korpus, Český akademický korpus (ČAK), Pražský závislostní korpus mluvené češtiny (PDTSC) a dvojjazyčný paralelní Pražský česko- anglický závislostní korpus (PCEDT). Vědecký přístup, metodologie, vlastní jazyková data a software, které byly v případě anotace všech uvedených korpusů zvoleny, jsou dnes uznávány i ve světě – jednak jsou publikovány v tzv. Linguistic Data Consortium, které je největší světovou základnou pro využití jazykových dat, jednak jsou jazyková data používána například v „soutěžích“ o co nejlepší modely struktury věty přirozeného jazyka. K tomu jistě přispívá i to, že to jsou po angličtině zdaleka největší jazyková data, která jsou ve světovém měřítku k dispozici. Je však také třeba říci, že příprava takových dat je vědecky náročná a samozřejmě i velmi nákladná.
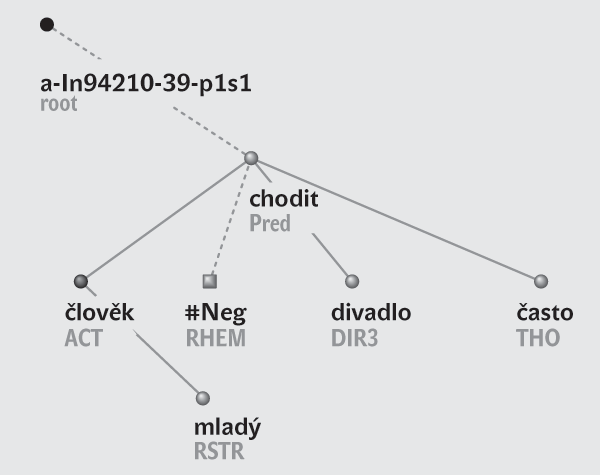
Zastavme se blíže u dvou anotovaných korpusů. Starší z nich je Pražský závislostní korpus, dnes dostupný ve verzi 2.0 (ufal.mff.cuni.cz/pdt2.0). Texty do něj byly vybrány z Českého národního korpusu a jsou charakteru publicistického, ekonomického a populárně-naučného. Anotace pokrývají tři roviny – rovinu tvaroslovnou, syntaktickou rovinu rozboru povrchové podoby věty a rovinu významovou (tektogramatickou). Na anotacích se pracovalo od roku 1996 a po deseti letech se dospělo k úctyhodnému objemu anotovaných dat. Vzhledem ke komplexnosti anotací je nejvíce dat anotováno morfologicky (2 miliony slov), část z nich na povrchové rovině (1,5 milionu slov) a z nich 0,8 milionu slov na rovině významové. Pro lepší představu demonstrujeme korpusová data anotací věty Mladí lidé nechodí do divadla často na všech 3 rovinách – viz obrázky 1, 2 a 3.
Mladším z korpusů, jehož existenci zde jenom zmíníme, je Pražský závislostní korpus mluvené češtiny (Prague Dependency Treebank of Spoken Czech, PDTSC). Je unikátní ještě z dalšího hlediska: Přebírá část dat z jedinečné databáze MALACH, kterou společně, z iniciativy Stevena Spielberga, vybudovala pracoviště univerzit v jižní Kalifornii, Marylandu a Baltimoru, ve spolupráci se Západočeskou univerzitou v Plzni, pracovištěm ÚFAL a výzkumným centrem IBM. Tato databáze obsahuje vzpomínky pamětníků přeživších holocaust (slovo malach znamená v hebrejštině kraloval či ustanovil za krále nebo také anděl), které jsou uloženy v archivu se 116 tisíci hodinami digitalizovaných nahrávek v 32 jazycích od 52 tisíc svědků nacistického holocaustu. Jeho část je on-line dostupná v knihovně MFF UK na Malostranském náměstí (ufal.mff.cuni.cz/cvhm/), další část je dostupná off-line jejím prostřednictvím z Univerzity v Jižní Kalifornii. Jsou to jedinečné videozáznamy, pro jejichž uchování a zpřístupnění bylo třeba řady modulů automatického rozpoznávání mluvené řeči. Pomocí strojem podporovaného automatického překladu byl vytvořen mnohojazyčný tezaurus umožňující katalogizaci údajů a efektivní způsob vyhledávání v archivech.
Počítačová lingvistika hrou
Expertní příprava jakýchkoli dat, tedy i anotovaných korpusů, je v mnoha ohledech nákladná aktivita, zejména vzhledem k potřebným lidským zdrojům, k její časové náročnosti a k nezbytným finančním prostředkům. Proto se hledají alternativní, levnější způsoby anotace, které se souhrnně označují jako crowdsourcing (síla davu). Jeden z jejich možných směrů využívá on-line her, u kterých se hráči primárně baví a na pozadí her generují data. Je-li hra pro hráče dostatečně atraktivní, dojde k naplnění přímé úměry, a sice čím více odehraných partií, tím více získaných dat.
Na pracovišti ÚFAL byla navržena a implementována hra PlayCoref (www.lgame.cz), při které hráči označují v odstavci slova, která odkazují k témuž. Například v již citovaném příkladě Ráno jsem přijel pro kytici růží pro nevěstu. Nelíbila se mi, představoval jsem si ji jinak hráč spojí zájmena mi a ji ve druhé větě buď s kyticí, nebo s nevěstou ve větě první.
Další alternativní způsob anotace navržený na ÚFAL je originální a souvisí s praxí výuky češtiny na našich školách, jejíž povinnou součástí je tvaroslovný a větný rozbor. Základní myšlenkou je zapojit do anotací přímo školáky. Navrhli jsme a implementovali editor větných rozborů Čapek (ufal.mff.cuni.cz/styx): školáci provedou rozbory „na počítači“ v editoru Čapek a my tyto rozbory transformujeme do korpusových anotačních schémat. Navýšíme tak objem dat potřebných pro procedury, na kterých všechny aplikace, které pracují s přirozeným jazykem, staví.
Závěr
Matematicko-fyzikální fakulta slaví letos šedesáté narozeniny, lingvistika na této fakultě narozeniny padesáté. Při příležitosti takto významných a částečně koincidujících jubileí chceme připomenout dlouholetou symbiózu dvou zdánlivě velmi odlišných oborů a poukázat na rozsah praktických aplikací založených na přirozeném jazyce, jejichž vývoj je otázkou současnosti a snad ne příliš vzdálené budoucnosti.
ÚFAL je pracovištěm, které je přátelsky nakloněné jak lingvistice, tak strojovému učení. Protože statistika je klíčovým pojmem strojového učení, je ÚFAL přátelsky spřízněn i se statistikou.
MATEMATICKÁ STATISTIKA
je vědní disciplína, která se zabývá metodami zpracování souborů dat. Tyto metody jsou založeny na induktivním přístupu, který na základě empirických znalostí (tj. zkušeností) hledá vztahy a zákonitosti mezi zkoumanými jevy, předpovídá výsledky pokusů a vyslovuje vědecké hypotézy. Empirické znalosti jsou ve statistice zastoupeny pozorováním souboru dat. Pracuje se s předpokladem, že pozorované údaje podléhají nějakým zákonitostem, které se snažíme odhalit, na druhou stranu jsou však zatíženy náhodným vlivem, který se v podstatě nevysvětluje, ale je třeba s ním při všech úvahách počítat. Nejbližším oborem matematické statistiky je pak teorie pravděpodobnosti, která se zabývá popisem a studiem náhodných jevů a odhalováním zákonitostí náhody.
Úplně první statistická procedura, která byla použita v rámci počítačového zpracování češtiny, a to v roce 1994, byla založena na tzv. skrytých markovovských řetězcích a byla aplikována na úlohu automatického tvaroslovného rozboru, tedy na automatickou identifikaci slovních druhů slov z textu spolu s identifikací kategorií danému slovnímu druhu příslušejících, např. pro podstatná jména rod, číslo a pád. Přístup na základě markovovských řetězců vychází z myšlenky, že pro tvaroslovný rozbor příslušného slova se využije informace z předešlého textu, tedy ze slov a jejich rozborů, které danému slovu v textu předcházejí. Pravděpodobnosti posloupností po sobě jdoucích slov a pravděpodobnosti rozborů slov se model naučí z textů, do kterých byly tvaroslovné informace doplněny ručně, tj. člověkem. Takováto učebnice má svůj název, a sice morfologicky anotovaný korpus (viz dále). Jak dlouhá má být historie, aby byl rozbor slova správný, bylo předmětem experimentování. S ohledem i na časovou složitost automatické identifikace se ukázalo, že dvě až tři slova z bezprostředně předcházejícího kontextu stačí na to, aby úspěšnost automatického tvaroslovného rozboru anglických textů byla vyšší než 98 %. Pro tvaroslovný rozbor českých textů vykazuje zapojení historie dvou i tří slov a jejich rozborů úspěšnost nižší (cca 95 %). To ale neznamená, že zapojením delší historie jsou výsledky automaticky lepší; je třeba lingvisticky fundovaného začlenění informace z rozšířeného kontextu, nikoli jen prostého mechanického prodloužení kontextu předcházejícího zkoumanému slovu. Vysvětlení nižší úspěšnosti tvaroslovného rozboru pro češtinu je třeba hledat v rozdílných vlastnostech češtiny a angličtiny, zejména ve vlastnostech slovosledu. Zatímco angličtina reprezentuje jazyk s poměrně pevným pořádkem slov ve větě, čeština je jazykem s volným slovosledem, proto kontext předcházejících slov poskytuje „méně“ informace o správném tvaroslovném rozboru.
Ke stažení
 článek ve formátu pdf [606,04 kB]
článek ve formátu pdf [606,04 kB]
O autorech
Doporučujeme

Když bahno teče jako ledovec

Ideologie v mapách, mapy v rukách ideologů 
