









Co je to gen?
Během éry sekvenčních analýz genomů vznikl významný požadavek registrovat geny z jednotlivých genomů podle jednotných zásad. Příklad průběžného řešení registrace představuje např. Wainův článek, který za gen považuje segment DNA, určující fenotyp/funkci, a v případě, že funkce není známa, gen může být charakterizován sekvencí, transkriptem nebo na základě homologie se sekvencí známého genu jiného organismu.1) Obsah definice se přizpůsobuje tak, aby bylo zachyceno co nejvíce kandidátů na hrdý titul gen vyznamenaný funkcí. Záměrem pravděpodobně je, že později bude snadnější některé nevhodně vybrané segmenty DNA, u kterých se funkce neobjeví, vypustit ze seznamu než po nich znovu pátrat. Tato definice svým úzkým vztahem k fenotypu je celkem v dobrém souladu s původním pojetím genu zakladateli klasické genetiky, kteří ovšem ještě neměli ponětí o tom, že DNA (popřípadě RNA) jsou nositeli záznamu genetické informace.
Výrazný posun v pojetí genu nastal v tzv. období postENCODE, kdy díky systematickým studiím konsorcia ENCODE byly prověřeny a výrazně doplněny dosavadní poznatky z genomové éry. Výsledkem tohoto snažení bylo mimo jiné i vytýčení, shrnutí a vyhodnocení současných problémů s definicí genu, které jsem v hrubých rysech načrtl ve dvou předcházejících částech tohoto seriálu.
Východiska pro aktualizaci definice genu
Problémy vytyčené v postgenomové a hlavně v postENCODE éře lze koncentrovat a roztřídit do několika hlavních skupin:
- Většina genomové DNA podléhá transkripci, která může probíhat překryvným způsobem, přičemž k překryvům může docházet jak při transkripci ze stejného řetězce, tak z protilehlých řetězců DNA. O funkci velké části transkriptů zatím nic nevíme. Vzniká otázka, zda nejde o jakýsi nefunkční odpad, anebo jen musíme počkat, až někdo funkci objeví.
- Sestřih, alternativní sestřih a vytváření spojených transkriptů vzniklých podle vzdálených oblastí genomové DNA patří k nejzávažnějším problémům komplikujícím pokusy o definici.
- Geny kódující polypeptidy se mohou také různě překrývat, a to nejen regulačními oblastmi, ale dokonce i oblastmi kódujícími sekvenci aminokyselin polypeptidu; informace uložená v určitých úsecích DNA může být exprimována různými alternativními způsoby, proměnlivými nejen ve způsobu transkripce a translace, ale i v úpravách transkriptu či polypeptidu.
- Úseky genů uplatňující se při regulaci a realizaci genové exprese, součásti genu v některých předcházejících pojetích definice genu, jsou často rozptýleny po rozsáhlé oblasti genomu a objevují se nejen před úsekem kódujícím primární transkript, ale i na místech značně vzdálených od promotoru (např. enhancery), uvnitř transkribované oblasti, a to jak v částech nekódujících, tak v částech kódujících výsledný polypeptid, a dokonce i za obvykle transkribovanou oblastí.
Kritéria pro aktualizovanou definici
Pokusem o systematické řešení těchto problémů na nejvyšší úrovni je článek Gersteina a jeho kolegů.2) Autoři, kteří se spolupodíleli na projektech konsorcia ENCODE, nejprve vytyčili pravidla, kterým by měla nová definice vyhovovat. Tento postup je třeba ocenit. Tak se hraje poctivě a srozumitelně, i když, jak uvidíte později, tento postup má i nebezpečná úskalí, kterých mohou kritici využít. „Ale tak to má ve vědě být,“ pochválil by filozof Karl Popper. Vědecké formulace mají být srozumitelné a jednoznačné, dotažené do kritizovatelné podoby, neboť věda je stálý proces nahrazování překonaných formulací formulacemi novými, které jsou v souladu s nejnovějšími poznatky:
- Nová definice by měla platit i pro dříve určené geny, aneb co bylo genem, nechť jím zůstane.
- Měla by být nezávislá na druzích organismů, aneb co platí pro bakterii, to platí i pro slona.
- Měla by být jednoduchá, bez nutnosti komentářů o mechanismech a bez uvádění výjimek, neboť co je složité, dlouho se neudrží.
- Měla by být praktická – vhodná pro zodpovězení základních otázek, např.: „Kolik je genů v lidském genomu?“
- Měla by být kompatibilní s biologickou a zejména genetickou nomenklaturou, neboť smysl se ukrývá v souvislostech.
Všimněte si, že většina uvedených kritérií není zaměřena ani tak na definovaný objekt, jako spíše na potřeby uživatelů definice, což naznačuje, že autorům šlo hlavně o to, aby definice plnila alespoň dočasně především svou roli při praktické komunikaci odborníků.
PostENCODE – definice genu
Výše uvedená kritéria si zcela logicky vynutila určitá zjednodušení a další zúžení obsahu pojmu gen ve srovnání s dřívějšími, až dosud probíranými definicemi.
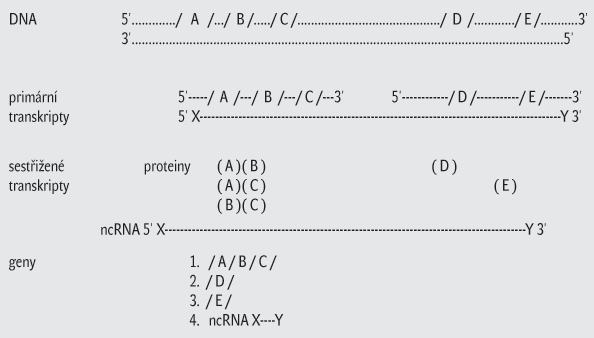 Gen v novém pojetí sice zůstává genomovou sekvencí (DNA, popřípadě RNA), ale zahrnuje jen sekvence přímo kódující funkční produkt (polypeptid či ncRNA3)), které nemusí být spojité. V tomto smyslu je nová definice spíše pokračováním úprav definice z molekulárně biologického období než návazností na pojetí zakladatelů z období klasické genetiky, kdy se definice spíše opírala o fenotypový projev genů za daných podmínek. Regulační a další průvodní oblasti, které se uplatňují při genové expresi, však do genů nejsou zahrnuty, neboť dělají neplechu a dokonce mohou být v některých případech sdíleny několika geny. Jindy se sice vztahují k jednotlivým genům, ale mohou se překrývat se sekvencemi kódujícími, jsou roztroušené, těžko se odhalují a analyzují.4) Nový je také důraz na funkčnost konečného produktu, a to nejspíš kvůli odlišení od pseudogenů.
Gen v novém pojetí sice zůstává genomovou sekvencí (DNA, popřípadě RNA), ale zahrnuje jen sekvence přímo kódující funkční produkt (polypeptid či ncRNA3)), které nemusí být spojité. V tomto smyslu je nová definice spíše pokračováním úprav definice z molekulárně biologického období než návazností na pojetí zakladatelů z období klasické genetiky, kdy se definice spíše opírala o fenotypový projev genů za daných podmínek. Regulační a další průvodní oblasti, které se uplatňují při genové expresi, však do genů nejsou zahrnuty, neboť dělají neplechu a dokonce mohou být v některých případech sdíleny několika geny. Jindy se sice vztahují k jednotlivým genům, ale mohou se překrývat se sekvencemi kódujícími, jsou roztroušené, těžko se odhalují a analyzují.4) Nový je také důraz na funkčnost konečného produktu, a to nejspíš kvůli odlišení od pseudogenů.
Pokud několik funkčních konečných produktů (buď ncRNA, anebo polypeptidů) sdílí překrývající se oblasti, genem může být celá sekvence zahrnující překrývající se úseky stejného typu (kódující buď ncRNA, anebo polypeptidy). Tato sdružená kódující sekvence je vytvořena pro produkty, které musí sdílet alespoň jednu část genové sekvence alespoň s jedním partnerem souboru, přičemž jednotlivé páry nemusí sdílet sekvenci stejnou. Sdílené sekvence musí být u genů určujících proteiny ve stejné kodónové fázi a kódující musí být stejné vlákno DNA.
Aby autoři aktualizované definice splnili příslib jednoduchosti, vytvořili jakousi zkrácenou formu definice, která zní: The gene is a union of genomic sequences encoding a coherent set of potentially overlapping functional products. (Gen je soubor genomových sekvencí kódující sdružený set potenciálně se překrývajících funkčních produktů.) Takováto zkratka definice ovšem nemůže sloužit jako návod k typování genů bez náležitého komentáře a návodného příkladu (viz obr. 1), aby byl její obsah dostatečně srozumitelný a obecně použitelný.
Komentář autorů k definici genu
Vyhovuje definice i spojitým kódujícím sekvencím? Pokud jsou geny spojité a kódující sekvence jednotlivých produktů se nepřekrývají, definice se mění na formu, která byla používána již dříve v období vzniku centrálního dogmatu pouze s tím rozdílem, že sekvence podílející se na regulaci a uskutečnění genové exprese se do genu nezařazují. Aktualizovaná definice se tudíž hodí jak pro geny prokaryotických, tak eukaryotických organismů. Spojité geny lze považovat za geny s nulovou nespojitostí bez možnosti alternativního skládání exonů.
 Jak chápat sdružování do jednoho genu v souvislosti s překryvnými produkty? Na sdružování se mohou podílet jen produkty stejného typu, buď polypeptidy, anebo ncRNA. Sdružování se uskutečňuje na úrovni „průmětu produktů“ do primární DNA sekvence, která je kóduje. V případě ncRNA je to sekvence komplementárních nukleotidů a v případě sekvence kódující pořadí aminokyselin je to také sekvence nukleotidů v DNA, ale tentokrát uspořádaných do tripletů odpovídajících kodónům. Pozor: při alternativní iniciaci transkripce spojené s posunem fáze mohou následnou translací vznikat polypeptidy s odlišnou sekvencí aminokyselin, takové sekvence se nesdružují. Obdobně mohou vznikat polypeptidy se zcela odlišnou sekvencí aminokyselin nebo ncRNA s odlišnou sekvencí nukleotidů třeba i v celém rozsahu produktu v případě výběru opačných řetězců DNA ze stejné oblasti, jako vzoru pro syntézu odpovídajících produktů. V těchto případech není sdružování sekvencí do jednoho genu možné, i když kódující sekvence leží ve stejné oblasti DNA.
Jak chápat sdružování do jednoho genu v souvislosti s překryvnými produkty? Na sdružování se mohou podílet jen produkty stejného typu, buď polypeptidy, anebo ncRNA. Sdružování se uskutečňuje na úrovni „průmětu produktů“ do primární DNA sekvence, která je kóduje. V případě ncRNA je to sekvence komplementárních nukleotidů a v případě sekvence kódující pořadí aminokyselin je to také sekvence nukleotidů v DNA, ale tentokrát uspořádaných do tripletů odpovídajících kodónům. Pozor: při alternativní iniciaci transkripce spojené s posunem fáze mohou následnou translací vznikat polypeptidy s odlišnou sekvencí aminokyselin, takové sekvence se nesdružují. Obdobně mohou vznikat polypeptidy se zcela odlišnou sekvencí aminokyselin nebo ncRNA s odlišnou sekvencí nukleotidů třeba i v celém rozsahu produktu v případě výběru opačných řetězců DNA ze stejné oblasti, jako vzoru pro syntézu odpovídajících produktů. V těchto případech není sdružování sekvencí do jednoho genu možné, i když kódující sekvence leží ve stejné oblasti DNA.
A co netranslatované oblasti mRNA? Netranslatované oblasti (5' a 3' UTR) se do genů nepočítají a navíc protein kódující transkripty, jejichž sekvence DNA se překrývají pouze v UTR nebo intronech, nemohou být sdruženy do jediného genu.
A co sekvence pro regulaci a zajištění genové exprese a stability? Tyto sekvence nejsou považovány za součást genu, nicméně autoři definice vytvářejí novou kategorii pro tyto oblasti s označením „oblasti s genem asociované“, které mohou být spojeny s několika geny (např. některé enhancery atp.).
Problémy s tzv. sestřihem v trans. Gen může, ale nemusí být jediným lokusem na RNA či DNA genomech. To znamená, že trans- -sestřihem vzniklé transkripty mohou patřit k jednomu genu.
Vysvětlení požadavku funkčnosti produktu. Autoři vyžadují funkčnost genového produktu. Přiřazení funkce může ovšem pozdržet na neurčito uznání genomické sekvence za gen. Autoři vytvářejí tento skrytý problém údajně proto, aby udrželi vztah genotypu a fenotypu s tím, že fenotyp se vztahuje k biochemické funkci molekulárních produktů genů. Funkčnost produktu je tudíž chápána tak, že není zaměnitelná s kódováním produktu, a pokud jsem výklad správně pochopil, ani např. s evolučním potenciálem kódující oblasti do budoucnosti. Dovedu si představit, že produkt by mohl nabývat funkci slabého ovlivnitele jiných důležitých procesů díky nějaké nespecifické anebo i specifické interakci s produkty silného účinku. Těmito jevy se ale článek v podstatě nezabývá.
Hlavní výhrady k novému pojetí genu
Nové pojetí genu sice opravdu platí nezávisle na organismu, svým dalším kritériím se však podle mého mínění autoři zpronevěřili.
Nová definice je dosti složitým souborem pravidel, co za gen považovat a co ne, který bez komentáře a příkladů není srozumitelný. Omluvou je, že u tak složitého pojmu můžeme tuto obtíž tolerovat, a je tudíž důvod toto kritérium považovat za pomocné a svým způsobem druhotné svým významem.
Definice není praktická, protože na jejím základě nelze snadno zodpovědět např. otázku: „Kolik má daný organismus genů?“, protože autoři požadavkem na znalost funkce „genem kódovaného produktu“ přijímání jednotlivých kandidátů na geny zamlžili a odložili v mnoha případech na neurčito. Omluvou ovšem je, že ani v předchozích případech nebyla situace často z jiných důvodů o moc lepší.
Na splnění dalších dvou kritérií se však již hledá omluva obtížně. Nová definice podle mého mínění nezajistila udržení kompatibility s ostatními genetickými a dalšími pojmy, ani nezajistila, aby to, co bylo dříve považováno za gen, zůstalo i nyní genem. Tyto nedostatky se pokusím doložit několika příklady.
Příklady nekompatibility genetických termínů a proměny rozsahu oblastí DNA zahrnutých do genu
Sledujete-li vývoj definice, tak jak byl podán v tomto seriálu, všimnete si, že ve fázi zakladatelů genetiky se kladl důraz na vztah genu k jeho projevu v nějaké vlastnosti organismu, jež se dědí. Výjimku tvoří, jakoby omylem, pouze definice z genomové éry uvedená na začátku tohoto článku, která datem svého vzniku i autory spadá do období molekulárně biologického, během kterého však lze pozorovat spíše postupný odklon od stěžejnosti vztahu k vlastnosti organismu za daných podmínek – od fenotypu. Posun šel směrem ke genům jako sekvencím kódujícím funkční ncRNA anebo polypeptidy jako konečné produkty genové exprese, přičemž se požadavek funkce vztahuje na produkt genu a ne na samotný gen. Ten funkci nesporně má, neboť zajišťuje produkci polypeptidu či ncRNA a tato funkce je dědičná, i kdyby třeba produkt nebyl shledán funkčním.
Mendel, Morgan a jejich bezprostřední následovníci opírali pojetí genu ve svých experimentech o jeho fenotypový projev (respektive o fenotypový projev alel genu) a o hledání změn fenotypu v potomstvu kříženců. Molekulárně biologická analýza mutantů používaných těmito autory a jejich žáky jasně ukázala, že alely s různým fenotypem se občas nelišily v sekvenci kódující, nýbrž v sekvenci jiné, dnes do genu nezapočítané, označované jako sekvence s genem asociované. Tedy, že alely otců zakladatelů nejsou totožné s alelami genů v novém pojetí. Rozdíly fenotypu pochopitelně nejsou vysvětlitelné na základě rozdílů v genotypu, pokud je genotyp odvozován jen od sekvencí odpovídajících genům v novém ENCODE-pojetí.
Je ale poněkud překvapivé, že když současné vědecké týmy mluví o sekvenování genomu, mají na mysli stanovení celé sekvence genomové DNA, popřípadě genomové RNA, což považuji za smysluplné. Celá genomová DNA se formou semikonzervativních kopií dědí z generace na generaci a v ní zaznamenaná informace určuje dědičné vlastnosti daného organismu. V rozporu s tímto tvrzením však současně nová definice zužuje obsah pojmu gen jen na sekvence kódující, přičemž jejich pojetí termínu funkce i kódování je podle mého mínění nestandardní.
Výsledkem této proměny nesporně je, že např. centromery, replikony a jiné genomové sekvence se pod deštník nové definice genu již nevejdou.
Obecné termíny kódování a kód jsou podle mého mínění používány ve vztahu k dědičnosti nevhodně a zmateně. Pokusím se poukázat na závažné důsledky této nesystematičnosti. DNA totiž nekóduje jen polypeptidy (zprostředkovaně přes transkripci a translaci), ale i vznik nové DNA (při replikaci) a RNA (při transkripci). Kódy využívané v těchto procesech jsou ovšem odlišné, ale jejich význam pro pochopení dědičnosti je zjevný. V prvním případě je to tzv. genetický kód a v dalších případech jsou to dvě odlišné varianty zákona komplementarity (zákony o párování komplementárních bází při replikaci, resp. při transkripci). Z tohoto hlediska je vzhledem k procesu replikace kódující veškerá buněčná DNA (či RNA virů), vzhledem k procesu transkripce pak DNA v transkribovaných oblastech (odpovídajících primární RNA).
Z toho ovšem plyne, že veškerá DNA, a to v obou komplementárních řetězcích, plní funkci předlohy pro vznik produktů, dceřiných DNA, kterými jsou vybavovány buňky dalších generací. Tedy veškerá DNA, která se replikuje, má nárok na zařazení mezi kandidáty na titul gen, a to po částech označovaných jako replikony, které jsou dlouhodobě považovány za jednotky replikace vybavené speciálním replikačním počátkem. Většina DNA je z jednoho nebo z obou řetězců také transkribována, a tak existuje s replikony se překrývající další síť genů založených na jednotkách transkribovaných ve formě primárních transkriptů.
Tím ale není kódování v souvislosti s dědičností ani zdaleka vyčerpáno. Např. kódování se uplatňuje i při procesech souvisejících s některými typy oprav DNA a s některými rekombinačními procesy (homologická rekombinace), u kterých má ovšem jednotka „pohyblivý“ charakter. Se zvláštním způsobem kódování se setkáváme i v souvislosti s prodlužováním telomer, kde je vzorem krátká RNA kopírovaná podle kódu, který se podobá transkripčnímu kódu. Při genových přeskocích retrotranspozonů a při reverzní transkripci virových RNA genomů je tomu podobně.
Ale ani tím výčet využívaných kódů nekončí. V předchozích případech se kódování uplatňovalo v souvislosti se syntetickým procesem, při kterém se vytvářely nové biomakromolekuly anebo jejich části o určitém, děděném pořadí podjednotek. Obrovské množství procesů souvisejících s dědičností nějaké vlastnosti organismu je však založeno nikoli na syntéze, ale na rozeznání určité sekvence nukleotidů anebo jen určitého obrazce skupin na struktuře DNA, či dokonce jen na dočasně vzniklé strukturní anomálii, která je často jen přibližně podmíněna sekvencí nukleotidů, anebo dokonce jen nějakou modifikací nukleotidů, jejíž vznik závisí na podmínkách. Příkladem je rozeznávání promotorů v souvislosti s iniciací transkripce, rozeznávání míst sestřihu primární RNA, rozeznávání některých počátků replikace, rozeznávání centromer, míst pro místně specifickou rekombinaci, míst pro restrikci atp.
Díky změnám pojetí genu se tudíž do kategorie „negenů“ dostala obrovská část genetické informace, která je, když nic jiného, sama jako produkt semikonzervativní replikace děděna z generace na generaci, ale současně zajišťuje dědění, neboť má funkci předlohy, podle které se kopíruje, tedy zajišťuje nepřetržité trvání genetické informace. Celá genomová DNA, resp. RNA v tomto smyslu kóduje sekvenci podjednotek v produktech, komplementárních řetězcích DNA, resp. RNA. Navíc část této DNA plní řadu dalších dědičných funkcí, z nichž jen kódování funkčních polypeptidů a ncRNA byly vzaty na milost a byly uznány jako právoplatné geny v postENCODE období. Funkce typu předloh pro transkripci nebo replikaci, určení pravděpodobnosti rekombinace DNA ve zvoleném úseku DNA mezi dvěma geny, potenciál k získání biochemické funkce a celá plejáda procesů založených na pouhém rozeznání sekvence nebo její části jaksi nestačí. Termín genetický kód jako by zatemnil naši schopnost uvidět jiné kódy, které se uplatňují při jiných procesech naplňujících také právoplatně naší představu o dědičnosti. Tyto kódy jsou respektovány speciálními skupinami „čtenářů genetické informace“ odlišnými od polymeráz a dalších pomocných faktorů, které se podílejí na čtení kódovaných záznamů v souvislosti se syntézou produktů (DNA, RNA a polypeptidů).
Plně uznávám přínos konsorcia ENCODE do diskuse o naplnění obsahu pojmu gen, a to zejména v souvislosti se získáním nových informací o expresi „kódujících“ genů a s řešením problémů se staršími definicemi, ale při vší úctě jsem přesvědčen, že navrženou definici nelze považovat za konečnou a všeobecně přijatelnou. Jde prozatím o stupínek na dlouhé cestě, který nejlépe vyhovuje těm, kteří se zabývají sekvencemi nukleotidů „kódujícími“ polypeptidy a „nekódující“ RNA. Trochu zapomínají na jev dědičnosti v jeho původní smysluplné celistvosti.
Gen padl, ať žije gen. Diskuse musí pokračovat, neboť definice postENCODE vyřešila do jisté míry jen konkrétní problémy určité skupiny genů, které kódují „funkční“ polypeptidy a ncRNA, ale pomíjí ostatní genetické elementy. Návrh do diskuse pro vývoj definice genu bude následovat po krátké přestávce.
Poznámky
1) Wain H. M. et al.: Guidelines for human gene nomenclature, Genomics 79, 464–470, 2002.
2) Gerstein M. B. et al.: What is a gene, post-ENCODE? History and updated definition, Genome Res. 17, 669–681, 2007.
3) ncRNA = non-coding, nekódující RNA.
4) Například promotory a operátory v prokaryotických operonech, sekvence vyznačující sestřih a nasedání na ribozom, místa pro vyznačení počátků a konců kódujících oblastí, sekvence zajišťující poločas trvání produktu atp.
Ke stažení
 článek ve formátu pdf [354,97 kB]
článek ve formátu pdf [354,97 kB]
O autorovi
Vladimír Vondrejs

Doporučujeme

Když bahno teče jako ledovec

Ideologie v mapách, mapy v rukách ideologů 
