










Geny a jejich čtení
| 5. 7. 1994Bizarní zacházení s genetickou informací, jak je popsáno v Lukešově článku, by ještě před dvaceti lety vyvolalo zděšení. V osmdesátých letech, kdy bylo objeveno, vyvolalo „jen“ údiv, dnes je podkapitolou v učebnici molekulární biologie. Tento průběh je ilustrací vývoje myšlení od r. 1941, kdy Beadle a Tatum přišli s teorií „jeden gen – jeden protein“.
Geny samotné nejsou jen holou sekvencí pro kódování proteinů. Značná část jejich sekvence nekóduje pořadí aminokyselin v proteinu, ale má charakter návěstí, informace, která např. umožní správné uchycení mRNA na ribozomu, nastavení začátku a konce čtení sekvence, regulaci proteosyntézy apod. Nastavení čtecího rámce je zvlášť důležité: vzhledem k tomu, že jednotlivé aminokyseliny v proteinu jsou kódovány trojicemi bází v mRNA, teoreticky existují tři různé možnosti čtení, z nichž obvykle jen jedna je smysluplná (viz ale níže!). Vše, co jsme si zatím řekli, by ještě nebylo tak překvapující, pokud by ta část mRNA, která bude přepsána do proteinu, zůstávala nezměněna a odpovídala sekvenci genu. Taková situace převládá u bakterií i u eukaryotních organizmů, které jsou běžnými laboratorními modely (kvasinky, houba Neurospora) a na kterých se celý děj zpočátku studoval. Jak se však ukázalo v sedmdesátých letech, u většiny eukaryotních organizmů jsou časté případy, kdy se zápis musí složitě upravovat a informace pro syntézu proteinu je dotvořena teprve v tomto procesu. Možné jsou také alternativní interpretace genetického zápisu. Zastavíme se u některých příkladů; ve světle toho, co s genetickým zápisem provádějí trypanozomy, nám budou připadat fádní, jsou však mnohem více rozšířeny.
U většiny eukaryotních organizmů lze v genu – mimo vzpomenutá návěstí na začátku a na konci – rozlišit dva druhy sekvencí: introny a exony, přičemž sekvence exonů tvoří často jen desetinu celé sekvence genu. Primární transkript genu (tzv. hnRNA) je mechanizmem sestřihu (splicingu) zbaven intronových sekvencí; informací pro syntézu proteinu jsou pouze exony. Navíc, podle kontextu, ve kterém se buňka nachází, lze introny a exony předefinovat – výsledkem takového alternativního sestřihu je několik variant přepisu téhož genu, tedy i několik variant proteinů kódovaných jediným genem.
Příkladem může být gen pro myozin (obrázek) nebo paleta proteinů mezibuněčné hmoty. Alternativní sestřih je jedním z vysvětlení existence intronů. Druhé – evoluční – vybočuje z rámce tohoto sdělení, takže jen stručně: Exony obvykle kódují strukturní a funkční podjednotky proteinů – domény. Díky tomu, že je exon v genu „interpunkčně“ jasně vymezen, lze jej přenést do jiných genů, a tak různé proteiny mohou sdílet některé domény. Kuriózním příkladem sestřihu je jeden z mitochondriálních genů, u kterého jeden z intronů nezaniká, ale je upraven na mRNA pro další protein.
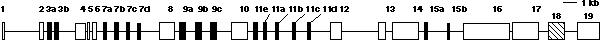 Z původní sekvence genu je tedy v molekule mRNA vlastní informací pro syntézu proteinů jen čtecí rámec. Sestřih musí být tak přesný, že i po vystřižení úseků dlouhých často tisíce bází zůstane čtecí rámec zachován (to vyžaduje přesnost na jediný nukleotid). Ukazuje se, že ani tento čtecí rámec nemusí být zápisem vždy jednoznačně definován.
Z původní sekvence genu je tedy v molekule mRNA vlastní informací pro syntézu proteinů jen čtecí rámec. Sestřih musí být tak přesný, že i po vystřižení úseků dlouhých často tisíce bází zůstane čtecí rámec zachován (to vyžaduje přesnost na jediný nukleotid). Ukazuje se, že ani tento čtecí rámec nemusí být zápisem vždy jednoznačně definován.
 Ribozom např. nemusí vždy na stop kodonu ukončit translaci, ale může v překladu pokračovat až po stop kodon následující. Jediná mRNA pak může sloužit jako matrice pro syntézu dvou proteinů, které sdílejí část sekvence. mRNA nemusí dokonce ani obsahovat celý čtecí rámec: ten je rekonstruován až během translace „přesmykem“ ribozomu o 1–2 nukleotidy. Nakonec i hotový protein může být ještě podroben sestřihu.
Ribozom např. nemusí vždy na stop kodonu ukončit translaci, ale může v překladu pokračovat až po stop kodon následující. Jediná mRNA pak může sloužit jako matrice pro syntézu dvou proteinů, které sdílejí část sekvence. mRNA nemusí dokonce ani obsahovat celý čtecí rámec: ten je rekonstruován až během translace „přesmykem“ ribozomu o 1–2 nukleotidy. Nakonec i hotový protein může být ještě podroben sestřihu.
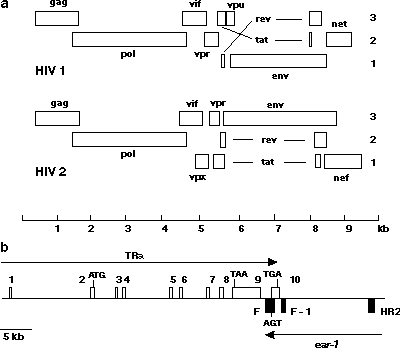
Dalším příkladem možnosti rozdílných interpretací genetického zápisu je překryv (overlap) genů. Jediná sekvence dvojité šroubovice DNA může teoreticky nést až šest zápisů pro protein (tři čtecí rámce na obou komplementárních vláknech). Z hlediska informatiky je ovšem takový překryv genů dost nepravděpodobný. Pravděpodobnost, že všechny takto kódované proteiny by měly smysluplnou funkci, je nepatrná, nemluvě o problémech s regulací takto provázaného systému. Přesto takové případy existují: u virů byl popsán trojnásobný překryv čtecího rámce (obrázek 2a). Překryv byl vysvětlován tím, že virus je omezen délkou DNA, kterou může vměstnat do svého pouzdra, a tímto způsobem „šetří místo“. Nedostatek místa v krátkém mitochondriálním genomu může být také příčinou překryvů popsaných u trypanozom, kvasinek a živočichů. Obdobné překrývající se geny byly však popsány i v jaderném genomu těch eukaryotních buněk, které v genomu obvykle místem nešetří. Jako příklad může sloužit komplikovaný překryv homeotických genů v genomu savců.
Byla popsána i varianta dvojího přepisu, tzv. overprinting, která se vyskytuje u 50 % všech virů, ale i u eukaryotních buněk. V tomto případě jsou ve výchozí situaci dva „normální“, nepřekrývající se geny, každý na komplementárním vlákně DNA. U jednoho z genů se mutací ztratilo znaménko (stop kodon) pro ukončení transkripce a gen se prodlouží o sekvenci, která však už tvoří komplementární vlákno sousedního genu (obrázek 2b). Tento komplementární zápis dá po translaci vznik naprosto novému strukturnímu motivu v proteinu.
O autorovi
Anton Markoš
Doporučujeme

Ničí ozon choleru? 

Jak se člověk stává biologem
