









Jak se vám líbí překlad (od stroje)?
| 5. 10. 2020Automatizovaný počítačový překlad textu je běžnou a důležitou aplikací umělé inteligence (samotný Google Translate přeloží více než 100 miliard slov denně). I když se kvalita strojového překladu za posledních deset let velmi zlepšila, stále se mělo za to, že se nemůže rovnat člověku (viz také Vesmír 91, 488, 2012/9).
Spolupráce mezi vědci z Ústavu formální a aplikované lingvistiky (MFF UK), Oxfordské univerzity a Google Brain však ukazuje, že lidské kvality lze nejen dosáhnout, ale v některých aspektech ji dokonce překonat. Nově vyvinutý systém hlubokého učení neuronových sítí (nazvaný CUBBITT) byl lidskými hodnotiteli posouzen jako přesnější než překlad provedený profesionální agenturou. I když byl lidský překlad stále hodnocen jako plynulejší, strojový překlad nebyl o mnoho horší (a jak ukazuje studie, není vždy snadné odlišit jej od lidského). Hlavní výhodou strojového překladu je, že mění informace obsažené v textu mnohem méně než člověk.
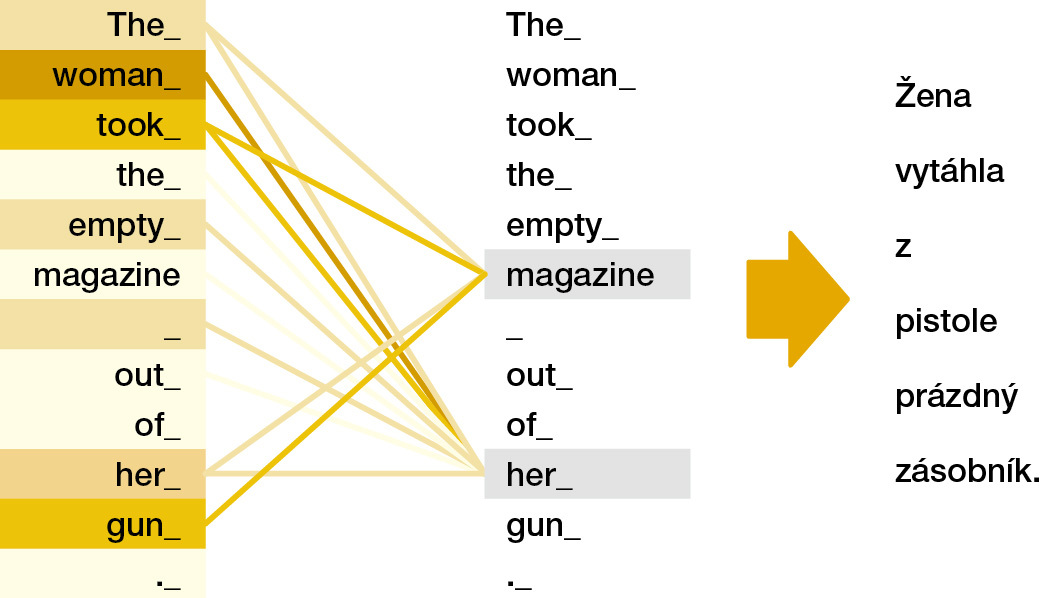
Pokrok v kvalitě strojového překladu je způsoben především dvěma faktory. Prvním z nich je koncept „sebe-pozornosti“, který do učení neuronových sítí vnesli výzkumníci Google Brain. Umožňuje síti učit se vztahy mezi vzdálenými prvky věty a používat je při překladu. Proto je „magazine“ na schématu níže správně přeložen jako „zásobník“, a nikoli jako „časopis“, protože neuronová síť ví, že „zásobník“ je v této větě spojen se zbraní. Využití pozornosti zároveň vedlo k drastickému zrychlení učení neuronových sítí ve srovnání s předchozími přístupy.
Druhým faktorem úspěchu je chytré využití jednojazyčných dat. Neuronové sítě se učí na datech, která obsahují text a jeho překlad. I když dlouhodobé úsilí vědců vedlo k vytvoření desítek milionů takových párovaných vět, stále to nestačí. Snad až překvapivě účinnou strategií je vzít česká data, strojově je přeložit do angličtiny a pak je použít pro anglicko-český překlad. Standardním přístupem je taková „umělá“ data smíchat s reálnými a dát je síti k učení. Tým z Univerzity Karlovy však ukázal, že lepších výsledků lze dosáhnout, pokud síť obdrží umělá a reálná data v delších blocích. Takový přístup může lépe „vytěžit“ znalosti a jazykové struktury v obou typech textu a úspěšně je uplatnit v překladu.
Je třeba poznamenat, že přeložené texty nebyly romány, ale zpravodajské články. Referenční lidský překlad zajišťovala odborná překladatelská agentura, nikoli elitní překladatel literatury (který by měl na překlad také mnohem více času). Navzdory těmto „ale“ je nicméně zřejmé, že umělá inteligence dosáhla dalšího významného milníku.
Současnou kvalitu strojového překladu můžete posoudit sami, vzhledem k tomu, že tento článek byl strojově přeložen z angličtiny. Jediné výjimky jsou v kurzívě (slovo „magazine“ bylo upraveno tak, aby zůstalo nepřeloženo). Překlad si můžete sami vyzkoušet na webových stránkách LINDAT/CLARIACH‑CZ (Projekt č. LM2018101), což je infrastrukturní projekt na podporu špičkového výzkumu v oblasti jazykových technologií a v oblasti společenských a humanitních věd i pro širokou veřejnost.
Popel M. et. al.: Nature Communication, 2020, DOI: 10.1038/s41467-020-18073-9
Ke stažení
 článek ve formátu pdf [938,91 kB]
článek ve formátu pdf [938,91 kB]
O autorovi
Jakub Tomek

Doporučujeme

Když bahno teče jako ledovec

Ideologie v mapách, mapy v rukách ideologů 
