









Strojový překlad
| 6. 9. 2012Strojový překlad (machine translation, MT) je neobyčejně přitažlivou úlohou na pomezí informatiky a lingvistiky. Zajímavý je komerčně i akademicky. Na světě se mluví třemi až osmi tisíci jazyky. Devět jazyků má více než 100 milionů mluvčích. Umožnit kontakty bez jazykových bariér je pro mnoho obchodníků i politiků mimořádně lákavou vidinou. Jen v Evropské unii je oficiálních jazyků 23, překlady oficiálních dokumentů a tlumočení ročně stojí zhruba miliardu EUR. Strojový překlad tak nabízí možnost drastických úspor.
Dokonalé hřiště pro vědce
 Z hlediska akademického je strojový překlad prvotřídním hřištěm pro řadu oborů. Kromě zmíněné lingvistiky, která zde může testovat své teorie, je překlad výzvou též pro statistiky a informatiky (zkuste strojově ohodnotit nepřeberné množství variant textu a rychle najít tu nejlepší formulaci) i ryzí softwarové inženýry. Dnešní praxi lze totiž shrnout takto: Vezměte texty odpovídající objemem 40 metrům anglických knih společně s jejich českými překlady. Najděte dvojice vět, které si odpovídají (bude jich cca 15 milionů), a každou vybavte větným rozborem. Na základě těchto ukázkových dat naučte počítače překládat. Překladu ovšem nelze upřít přesah do umělé inteligence a filozofických otázek: Copak je možné překládat, aniž bychom stroj napřed naučili textu „rozumět“? Praxe ukazuje, že hranice tohoto přístupu dovolují dojít překvapivě daleko. Badatel ve strojovém překladu má příležitost doslova si sáhnout na produkty lidské mysli a zkusit je strojově napodobit. Takovou šanci pracovat s hmatatelnými a měřitelnými daty mnohé obory kognitivních věd stále nemají.
Z hlediska akademického je strojový překlad prvotřídním hřištěm pro řadu oborů. Kromě zmíněné lingvistiky, která zde může testovat své teorie, je překlad výzvou též pro statistiky a informatiky (zkuste strojově ohodnotit nepřeberné množství variant textu a rychle najít tu nejlepší formulaci) i ryzí softwarové inženýry. Dnešní praxi lze totiž shrnout takto: Vezměte texty odpovídající objemem 40 metrům anglických knih společně s jejich českými překlady. Najděte dvojice vět, které si odpovídají (bude jich cca 15 milionů), a každou vybavte větným rozborem. Na základě těchto ukázkových dat naučte počítače překládat. Překladu ovšem nelze upřít přesah do umělé inteligence a filozofických otázek: Copak je možné překládat, aniž bychom stroj napřed naučili textu „rozumět“? Praxe ukazuje, že hranice tohoto přístupu dovolují dojít překvapivě daleko. Badatel ve strojovém překladu má příležitost doslova si sáhnout na produkty lidské mysli a zkusit je strojově napodobit. Takovou šanci pracovat s hmatatelnými a měřitelnými daty mnohé obory kognitivních věd stále nemají.
Přehnaná očekávání
 Již s prvními počítači v éře Johna von Neumanna a Alana Turinga se objevily naděje na plně automatický převod textů z jednoho jazyka do druhého. V roce 1954 IBM vydává tiskovou zprávu o překladu z ruštiny do angličtiny, kde mj. cituje vysoká očekávání zúčastněných badatelů. Do tří či pěti let měl být překlad podstatných jazykových jevů pro více jazyků realitou. Obrovský rozpor mezi těmito nadějemi a skutečnými výsledky, jichž se v příštích letech podařilo dosáhnout, pak v sedmdesátých letech zcela zablokoval přísun prostředků do této oblasti výzkumu.
Již s prvními počítači v éře Johna von Neumanna a Alana Turinga se objevily naděje na plně automatický převod textů z jednoho jazyka do druhého. V roce 1954 IBM vydává tiskovou zprávu o překladu z ruštiny do angličtiny, kde mj. cituje vysoká očekávání zúčastněných badatelů. Do tří či pěti let měl být překlad podstatných jazykových jevů pro více jazyků realitou. Obrovský rozpor mezi těmito nadějemi a skutečnými výsledky, jichž se v příštích letech podařilo dosáhnout, pak v sedmdesátých letech zcela zablokoval přísun prostředků do této oblasti výzkumu.
Dnešní vize je do značné míry opatrnější. Neočekáváme, že se podaří dosáhnout plně automatického překladu vysoké kvality bez omezení oblasti, o níž se píše, a případně stylu, jímž se píše. Na druhou stranu v celé řadě situací strojový překlad může dobře posloužit i přes nedostatečnou kvalitu (např. zpřístupnění webových stránek v řeči, kde ani písmo nedokážete přečíst) a v úzce vymezených úlohách (např. heslovitý návod k nějakému výrobku a zejména jeho aktualizace s novou verzí) je již dnes bezpečně výhodnější než lidský překlad.
Lingvisté versus statistici
 Podobně, jako se zpočátku v extrémech pohybovala očekávání o překladu, lze na překladu demonstrovat stále těsnější sbližování dříve nesmiřitelných proudů. Warren Weaver (1949) nahlížel na překlad jako na dešifrovací úlohu, kde humanitní vědy nemají své místo: „Mám ruský text, budu však předstírat, že je ve skutečnosti napsán anglicky a jen zašifrován do neznámých symbolů. Stačí tu šifru rozluštit.“ Lingvista Noam Chomsky (1969) statistické teorie zatracoval: „Pojem ,pravděpodobnost věty‘ je zcela k ničemu, a to při jakékoli známé interpretaci.“ Fredericku Jelinkovi (v osmdesátých letech v IBM, později působil i v Ústavu formální a aplikované lingvistiky Matematicko-fyzikální fakulty Univerzity Karlovy, ÚFAL MFF UK) je vkládána do úst tato zkušenost: „Kdykoli z týmu vyhodím lingvistu, přesnost se zlepší.“ Hermann Ney (RWTH Aachen University), původem fyzik, naopak smysl lingvistiky při konstrukci překladačů vidí jasně: „Machine Translation = Linguistic Modelling + Statistical Decision Theory“.
Podobně, jako se zpočátku v extrémech pohybovala očekávání o překladu, lze na překladu demonstrovat stále těsnější sbližování dříve nesmiřitelných proudů. Warren Weaver (1949) nahlížel na překlad jako na dešifrovací úlohu, kde humanitní vědy nemají své místo: „Mám ruský text, budu však předstírat, že je ve skutečnosti napsán anglicky a jen zašifrován do neznámých symbolů. Stačí tu šifru rozluštit.“ Lingvista Noam Chomsky (1969) statistické teorie zatracoval: „Pojem ,pravděpodobnost věty‘ je zcela k ničemu, a to při jakékoli známé interpretaci.“ Fredericku Jelinkovi (v osmdesátých letech v IBM, později působil i v Ústavu formální a aplikované lingvistiky Matematicko-fyzikální fakulty Univerzity Karlovy, ÚFAL MFF UK) je vkládána do úst tato zkušenost: „Kdykoli z týmu vyhodím lingvistu, přesnost se zlepší.“ Hermann Ney (RWTH Aachen University), původem fyzik, naopak smysl lingvistiky při konstrukci překladačů vidí jasně: „Machine Translation = Linguistic Modelling + Statistical Decision Theory“.
Dva přístupy k překladu
Seznamme se nyní podrobněji se dvěma velmi odlišnými přístupy k překladu. ÚFAL oba do hloubky studuje a rozvíjí. Každoroční celosvětové soutěže ve strojovém překládání nám pak umožňují systémy porovnávat a navzájem obohacovat (obr. 1).1)
Frázový statistický překlad
 Frázový překlad pracuje se slovy jako nedělitelnými a izolovanými jednotkami, počítač tedy „nevidí“ žádný vztah mezi slovy kočka a kočkou, natožpak kočka a kocour, nebo dokonce kočka a micinka. Věta je prostě posloupnost různobarevných obdélníčků, kterou je třeba převést na jinou posloupnost jinak barevných obdélníčků.
Frázový překlad pracuje se slovy jako nedělitelnými a izolovanými jednotkami, počítač tedy „nevidí“ žádný vztah mezi slovy kočka a kočkou, natožpak kočka a kocour, nebo dokonce kočka a micinka. Věta je prostě posloupnost různobarevných obdélníčků, kterou je třeba převést na jinou posloupnost jinak barevných obdélníčků.
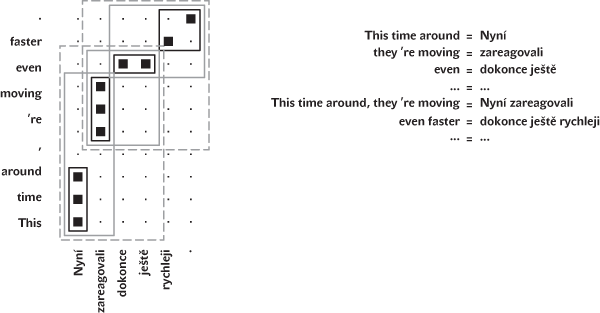
Překládat je v tomto modelu možné díky obrovskému objemu vět, které již dříve přeložili lidé. Počítač věty a jejich překlady k sobě spáruje a v rámci každého páru pak najde, která slova si navzájem přibližně odpovídají. Z takto „zarovnaných“ textů se získá „překladový slovník“. Na rozdíl od běžných slovníků jsou v něm třeba i posloupnosti deseti slov (mezi něž ovšem systém nemá oprávění vložit žádné další slovo) a především jsou slova uvedena ve všech tvarech, jak byla v datech spatřena (obr. 2).
Po zadání vstupní věty počítač zkusí všechny varianty „rozstříhání“ této věty na několikaslovné úseky (nelze mluvit o větných členech ap., úseky zcela ignorují lingvistická pravidla). Každý úsek je přeložen pomocí zmíněného slovníku. Z mnoha možností překladů úseků jsou vybrány takové (a v takovém pořadí), které na sebe nejlépe navazují.
 Technicky je samozřejmě systém složitější. Volba nejlepší věty z mnoha kandidátů (viz obr. 3.) je ve skutečnosti ovlivněna hned několika nezávislými „modely“. První z nich, tzv. překladový model, jsme právě popsali: číselně vyjadřuje, jestli jsou v kandidátské větě použity spíše fráze, které podle zmíněného automatického překladového slovníku dobře odpovídají úsekům ve vstupní větě.
Technicky je samozřejmě systém složitější. Volba nejlepší věty z mnoha kandidátů (viz obr. 3.) je ve skutečnosti ovlivněna hned několika nezávislými „modely“. První z nich, tzv. překladový model, jsme právě popsali: číselně vyjadřuje, jestli jsou v kandidátské větě použity spíše fráze, které podle zmíněného automatického překladového slovníku dobře odpovídají úsekům ve vstupní větě.
Druhý velmi významný model je tzv. jazykový model. Jeho úkolem je zhodnotit kandidáta izolovaně, bez ohledu na vstupní větu. Hlavní výhodou separátního jazykového modelu je fakt, že může být natrénován na jednojazyčných textech. Těch je typicky k dispozici řádově více, a model je tedy přesnější. Používá se tzv. n-gramový jazykový model, který pro danou kandidátskou větu číselně vyjadřuje, nakolik jsou jednotlivé (překrývající se) úseky o n slovech „známé“ z trénovacích dat. Čím typičtější n-tice slov jazykový model vidí, tím je spokojenější. Omezené okénko n slov vede často k větám lokálně plynulým, ale bez celkové struktury. Chytřejší modely, které se snaží kontrolovat gramatiku věty, přes mnohaleté úsilí nedávají zatím lepší výsledky.
Hloubkově-syntaktický překlad
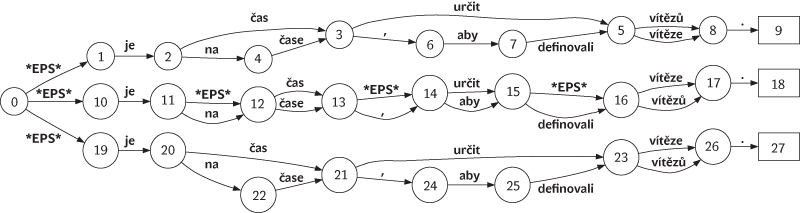 Překlad založený na větném rozboru má ambici zajistit gramatický výstup. Nepracuje proto se surovou podobou věty, ale převádí ji postupně na tzv. povrchovou a hloubkovou rovinu reprezentace, jakýsi stromeček větných členů a závislostí mezi nimi. K převodu do druhého jazyka dojde právě v hloubkové reprezentaci, překladá se tedy „strom na strom“. Překladový slovník proto neobsahuje všechny tvary slov, ale je jen tvar základní. Za závěrečné skloňování a časování při generování cílové věty ze stromu v cílovém jazyce je zodpovědná samostatná komponenta systému (obr. 4 a 5).
Překlad založený na větném rozboru má ambici zajistit gramatický výstup. Nepracuje proto se surovou podobou věty, ale převádí ji postupně na tzv. povrchovou a hloubkovou rovinu reprezentace, jakýsi stromeček větných členů a závislostí mezi nimi. K převodu do druhého jazyka dojde právě v hloubkové reprezentaci, překladá se tedy „strom na strom“. Překladový slovník proto neobsahuje všechny tvary slov, ale je jen tvar základní. Za závěrečné skloňování a časování při generování cílové věty ze stromu v cílovém jazyce je zodpovědná samostatná komponenta systému (obr. 4 a 5).
Z technického hlediska je systém s hloubkovým překladem vystavěn z mnoha součástek velmi odlišného charakteru. Pro počáteční větný rozbor se používají statistické nástroje natrénované na závislostních korpusech, podobně překladový slovník je sestaven automaticky z již přeložených textů. Při překladu stromu na strom je však též prostor uplatnit celou řadu stabilních lingvistických pravidel, která charakterizují rozdíly mezi zdrojovým a cílovým jazykem ať už z hlediska gramatiky či jen formalit zápisu této syntaktické reprezentace.
Kombinace strojového překladu
Je zřejmé, že chyby, jichž se dopustí frázový a hloubkový překlad, budou velmi odlišné. V praxi se ukazuje, že frázový překlad lépe zvládá volbu překladových ekvivalentů a přirozeně též ustálená spojení (pokud tvoří souvislou posloupnost slov), naproti tomu delší věty často nejsou srozumitelné, protože překlad nehlídal celkovou strukturu věty. Hloubkový překlad trpí opačným problémem: věty jsou správně vystavěny, ale nedávají smysl kvůli nevhodně zvoleným překladům jednotlivých slov.
Nabízí se proto systémy kombinovat a těžit z předností obou. Ovšem i ke kombinování lze přistupovat rozdílně: buď bude mít poslední slovo frázový model (obr. 6), nebo se naopak můžeme pokusit prosadit povinná gramatická pravidla jako shodu podmětu s přísudkem na výstup frázového překladu. Druhá metoda se nedávno ukázala jako velmi úspěšná, je však jen otázkou času, kdy se podaří gramatická pravidla zabudovat i do plně statistických systémů.
Poznámky
Ke stažení
 článek ve formátu pdf [504,47 kB]
článek ve formátu pdf [504,47 kB]
O autorovi
Ondřej Bojar
Doporučujeme

Když bahno teče jako ledovec

Ideologie v mapách, mapy v rukách ideologů 
