





I geografie má velká data
| 1. 11. 2021Práce s rozsáhlými soubory dat patří ke geografii odnepaměti. Čím podrobněji se snažíme popsat svět kolem nás, tím více dat musíme vytvořit, a to často s poměrně složitou strukturou. Geografie navíc také pracuje i s jejich polohou. Pojďme se podívat na problematiku velkých dat z hlediska geografie a geoinformatiky – čím nám pomáhají, ale také jaká úskalí nás při jejich zpracování čekají.
Návštěva u fraktálů
Náš výlet do říše geografických dat začneme u článku B. Mandelbrota How Long Is the Coast of Britain? Statistical Self-Similarity and Fractional Dimension, ve kterém představil paradox délky pobřeží. Na délce pobřeží Velké Británie ukázal, že hodnota, kterou naměříme, záleží na rozlišení našeho měřidla. Pokud budeme měřit hypotetickou dvousetkilometrovou tyčí, výsledná vzdálenost bude kratší, než kdybychom měřili tyčí padesátikilometrovou. Kratší tyč totiž dokáže vystihnout více detailů, takže budeme měřit klikatěji.
Mandelbrot pak pokračuje matematickým popisem tohoto typu křivek a diskusí, zda určovat délku má v těchto případech vůbec smysl. My si z toho můžeme odnést ponaučení, že rozlišení, s jakým sbíráme data, může hrát zásadní roli v tom, jak jsou data následně využívána a jaké informace jsme díky nim schopni získat.
Moderní technologie sběr dat neustále zpřesňují. Družicové snímky máme k dispozici s rozlišením pod půl metru na jeden pixel, rozmáhá se laserové skenování z letadel a optické snímkování z dronů, běžně se používají profesionální GPS přijímače, které měří velmi přesně a v reálném čase.
Paradoxně ne vždy technologicky zvýšená přesnost znamená, že výsledná data budou věrnější. Staří geometři dokázali zmapovat terén jen s minimem naměřených bodů. Zaměřovali se totiž na hlavní charakteristické znaky mapovaného území. Změřili lomové body hranic lesa, osu či okraj cesty, nezapomněli zanést každý terénní zlom, patu svahu, hřbetnici kopců nebo nejnižší bod údolí. Laserovému skeneru jsou tato místa jedno. Skenuje vše, nad čím přelétá, a v nasnímaném mračnu bodů musíme tyto charakteristické rysy terénu identifikovat matematickými algoritmy.
A to vlastně nastiňuje náš hlavní problém s velkými daty: Jak z objemných souborů dat získat informace, které jsou pro nás užitečné?


Co se všemi daty dělat?
Kartografie má s extrahováním informací z dat zkušenosti. Shrnout rozsáhlá data z mnoha zdrojů do jedné mapy je ostatně její podstatou. Metody a postupy, které se pro tvorbu tematických map využívají, se proto s úspěchem dají použít i na zpracování velkých dat. S příchodem počítačového zpracování a interaktivních map navíc vznikají další metody vizualizace.
První tradiční metodou je generalizace. Při tvorbě mapy republiky například nepotřebujeme data o každém potůčku s každou jeho zákrutou. Kartograf vybere jen ty vodní toky, které se na mapě mají objevit, a jejich průběh generalizuje. To znamená, že zjednoduší jejich vzhled tak, aby zachoval jejich charakteristický tvar a polohu. Výsledkem je ladně zakřivená linie, která si ponechává všechny důležité prostorové vztahy s okolními prvky, a nikdy se tak nestane, že by generalizovaná řeka tekla na druhé straně silnice než ve skutečnosti.
I databáze se při práci s prostorovými daty uchylují k určité generalizaci, i když v jejich případě je cílem především urychlení prostorových operací a snazší vyhledávání správných prvků. Proč je to důležité? Představme si například databázi parcel v ČR, kterých je přes 22 milionů. Když si chceme tato data v digitální mapě zobrazit, software by musel parcelu po parcele kontrolovat, zda spadá do oblasti, na niž se právě díváme. Proto se v databázi vytváří tzv. prostorový index, který tyto operace nesmírně urychlí. Často má podobu obdélníku opsaného kolem každého prvku, což reprezentuje jeho velmi zjednodušený tvar. S ním pak počítač umí zacházet velice efektivně. Může si je ještě také roztřídit do nadřazených oblastí (představme si to jako značku, která říká například „toto je na severu“), a to mu práci dále zjednoduší.
A tak když budeme po počítači chtít zobrazit parcely příště, nejprve zjistí, na jaké území se díváme, pak sáhne do správné nadřazené oblasti a podle opsaných obdélníků vybere jen parcely, které by mohly zasahovat na území, jež sledujeme. A ty pak konečně bod po bodu zkontroluje, zda na něj opravdu zasahují. Je vidět, že čím rozsáhlejší data jsou, tím větší je i potřeba jejich indexování.

Agregace dat

Druhou důležitou metodou je agregace neboli shlukování. Vidíme-li v mapě desetitisíce bodů, nejspíš z ní nevyčteme vůbec nic. Budeme zahlceni. Navíc i software bude mít problémy se zobrazováním tolika prvků najednou. Proto je namístě data agregovat buď do určitých oblastí, nebo k existujícím prvkům, se kterými mají tato data vztah.
Průběžná měření na meteorologických stanicích je lepší zobrazit spíš ve formě průměrné, maximální nebo minimální teploty za určitý čas než ukazovat každé měření zvlášť. V případě událostí, jako jsou například požáry, je zase lepší sumarizovat je po obcích nebo po hasičských okrscích. Podobně s daty o výskytu blesků je lepší pracovat tak, že si území rozdělíme na čtvercové nebo hexagonální buňky, kterým přiřadíme počty blesků, jež se v dané buňce vyskytly.
Z tisíců či milionů záznamů tímto způsobem získáme datové sady o velikosti, se kterou se dá na běžném hardwaru pracovat a kterou dokážeme našimi smysly pojmout.
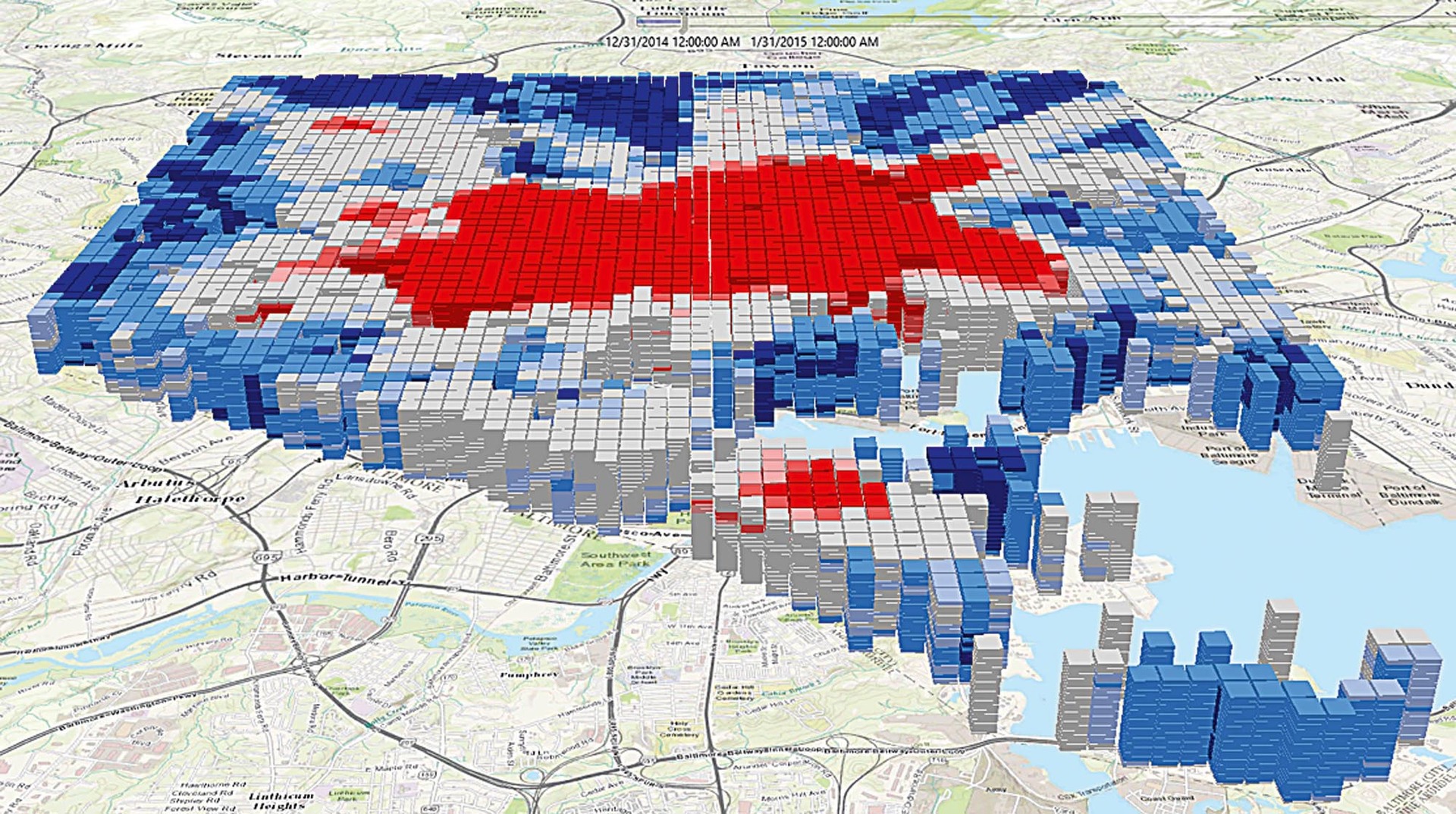
Časoprostorové kostky
Počítačové zpracování umožňuje i nové druhy vizualizace. Jedním z nich je tzv. časoprostorová kostka, která vychází z dat agregovaných v buňkách, přičemž data jsou navíc rozdělena do časových intervalů (týdnů, měsíců) a při vizualizaci jsou tyto roviny zobrazené nad sebou. Čas v této kostce probíhá „zespoda nahoru“, a my tak můžeme sledovat vývoj veličiny nejen v prostoru, ale i v čase.
Vizualizace formou časové kostky se obvykle využívá společně s hot-spot analýzou a zobrazená data tak obvykle ukazují trendy, tedy významné shluky nízkých či vysokých hodnot.
Bez techniky to nejde
I přes existenci řady postupů a metod (ty výše uvedené byly pouhým příkladem) je práce s velkými objemy dat velmi náročná na výpočetní techniku, a vyžaduje proto specifické technologické postupy. Předně to je využívání paralelního zpracování, které data rozdělí na několik dílů, a výpočet je pak prováděn současně na různých procesorech. Velmi časté je také distribuované ukládání dat, kdy je databáze rozdělena na menší části, které jsou umístěny na různých místech.

Práce s velkými daty je, jak vidět, náročná úloha a v budoucnu bude určitě přibývat dat, která tímto způsobem můžeme zpracovávat. Zejména s rozvojem internetu věcí se zpřístupňují nejrůznější chytré senzory a navigace v autech. Vzrůstá i podíl dat, která se uchovávají v databázích, oproti těm, která se vyskytují v nestrukturované podobě. Případy, kdy budeme muset používat nástroje pro velká data, budou častější.

Vydestilovat to nejdůležitější
Cílem zpracování velkých dat je získat nové informace. Různé způsoby sumarizací, agregací a prostorových analýz zase směřují k tomu, abychom získali (alespoň v rámci možností) srozumitelnou odpověď. K dispozici přitom máme mnohem více než pouhé zobrazení výsledků v mapě. Začlenit totiž můžeme celou řadu interaktivních funkcí, jako jsou například grafy, které se překreslují na základě vybraných prvků, nebo prohlížení v různých stupních podrobnosti (některé shluky dokážeme identifikovat pouze při velkém přiblížení). To všechno dokážou současné geografické informační systémy zajistit například ve webové aplikaci, takže k přístupu k těmto vizualizacím není potřeba žádný speciální software. Uživatelé tak mohou technologii nechat v pozadí a soustředit se především na interpretaci dat.
Ke stažení
 článek ve formátu pdf [355,23 kB]
článek ve formátu pdf [355,23 kB]
O autorovi
Jan Souček

Další články k tématu
(Ne)chemické toulky chemickým prostorem
Digitální ekosystém
Datová revoluce v biologii
Divoká plavba mořem dat
Doporučujeme

Divocí kopytníci pečují o krajinu

Relativistický čas – čas našeho světa
